The previous article Basic architectural terminology introduced service oriented architecture and micro-services.
This article will take a deeper dive into how to design an application using a micro-service architecture.
A key question is how many separately deployable services an application should be split up in.
To put some labels on different options:
The choice of option here is not trivial.
Some options may be more in fashion than other, but the reality is that there is not one option that is best for all cases. There are tradeoffs and the best option for a specific case depends on the specific context.
Splitting service X up in services X1,...,Xn has some potential advantages:
and some potential disadvantages:
Regarding transactional integrity the options are:
From a practical perspective a single service and simple transactions are almost always the best option.
So the key questions to ask when evaluating whether some functionality should be in N services or in a single service are:
Decision logic:
| Question | Answer => decsion |
|---|---|
| is it relevant run a different number of instances of the N services? | no => no reason to split yes => reason to split |
| does it make sense to have N-1 services running if 1 service are down? | no => no reason to split yes => reason to split |
| will any of the services be frequently updated? | no => no reason to split yes => reason to split |
| are there a need for transactional integrity between the N services? | no => can split yes => should not split |
| how many high volume interactions between the N services? | few => can split many => should not split |
This can be operationalized to a process:
Is the result perfect? Probably not. Is the result good? Maybe. Is the result relevant as a starting point? Yes.
You may have heard experts say that the best way to do micro-services is to do it the second time and wonder why that is the case if the above process works. As always the devil is in the details. Step 5-10 above are certainly doable. But step 1-4 above are the tricky ones. Getting them wrong will make the split in services wrong even when following the process.
Let us create an example - a simple web shop.
Functionality:
And let us see different ways to split the application.
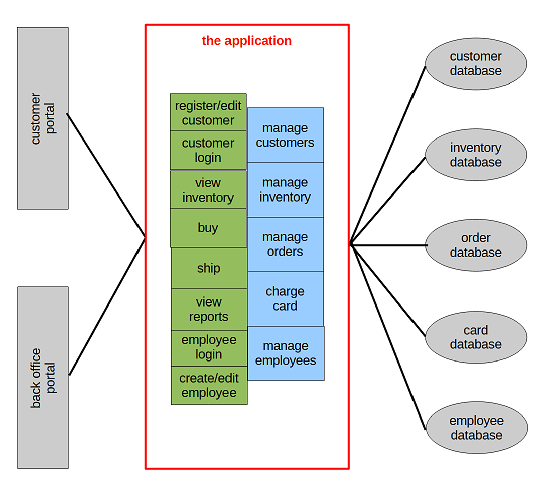
Everything in one application.
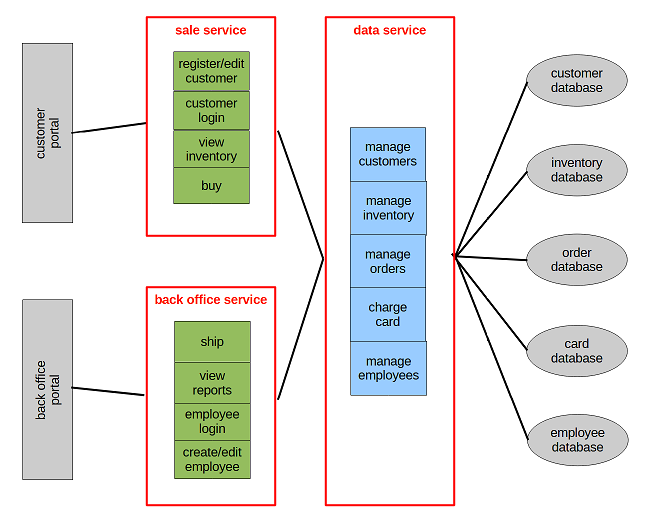
Split in 3 services (sale, back office and data).
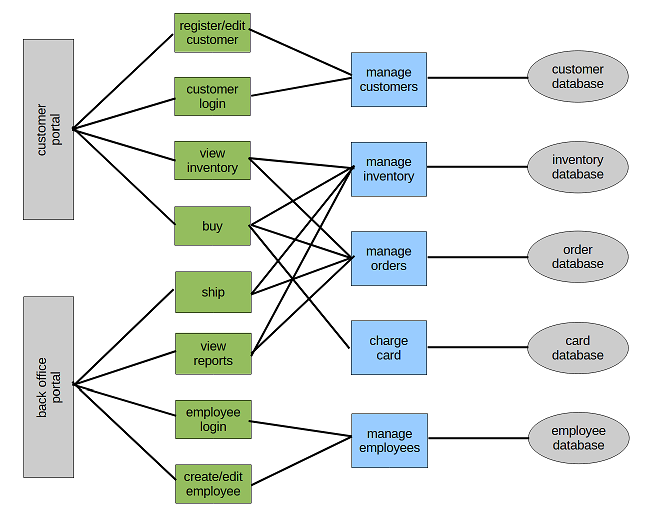
Split in 8 services (customer, sale, ship, reports, employee, inventory, order and card).
One functionality becomes one service.
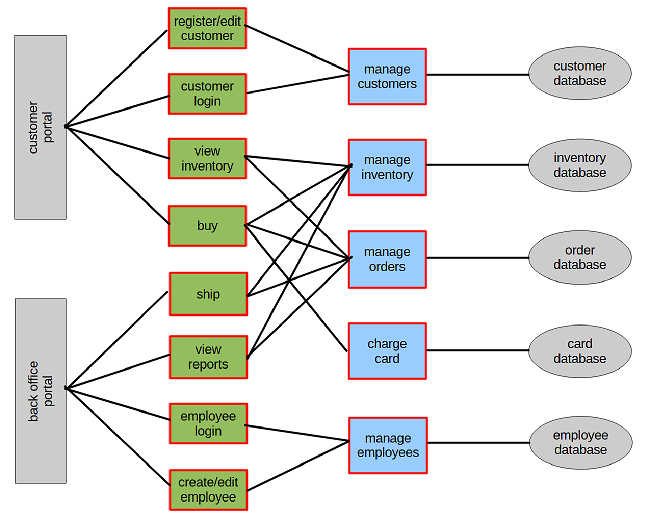
We follow the process step by step.
identify functionality F1..Fn
We got per above:
We have two transactional bundles:
We have thirteen critical dependencies:
Independent scalable:
Not required to always run:
Frequent upghrades:
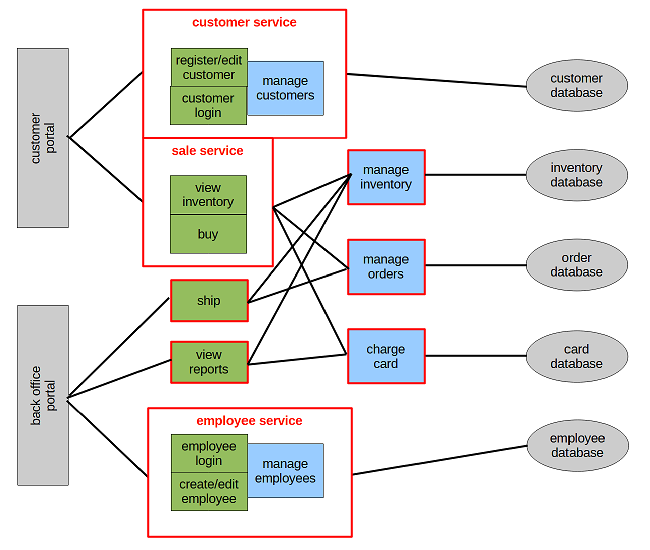
We have two overlapping transaction bundles so we move them to a core service:
View inventory interacts a lot with core service and there are no big benefits from having it seperate, so it goes into core service.
View reports interacts a lot with core service but there is a big benefit from having it seperate due to the frequent upgrades, so it does not go to core service.
View reports, manage customers and manage employees each has two interactions so they become services.
Register/edit customer and customer login go to customer service.
Create/edit employee and employee login goes to employee service. The fact that create/edit employee is not required to always run is not sufficient to split it out in a separate service.
Nothing to do.
Nothing to do.
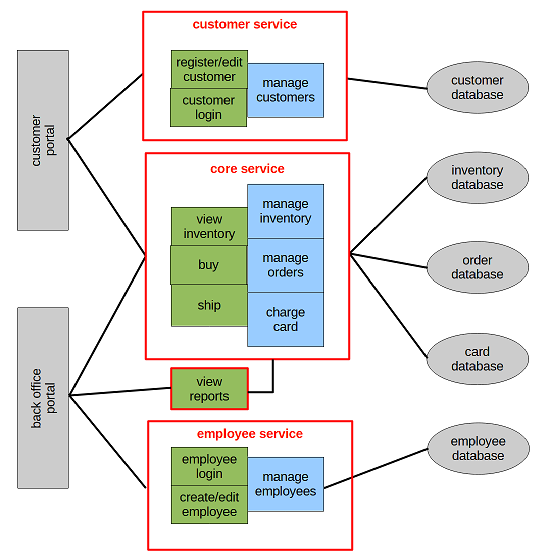
Is this a micro-service architecture? Or a mini-service architecture? Or a hybrid? I would be inclined to call it a hybrid with 1 mini-service and 3 micro-servers. But it does not matter what we label it - it only matters if it works!
The process in the previous section can actually be implemented as code with just a few practical assumptions.
Code:
package archadv;
public class Functionality {
private String name;
private boolean scalable;
private boolean optional;
private boolean updateable;
public Functionality(String name, boolean scalable, boolean optional, boolean updateable) {
this.name = name;
this.scalable = scalable;
this.optional = optional;
this.updateable = updateable;
}
public String getName() {
return name;
}
public boolean isScalable() {
return scalable;
}
public boolean isOptional() {
return optional;
}
public boolean isUpdateable() {
return updateable;
}
@Override
public String toString() {
return name;
}
}
package archadv;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public abstract class BaseServiceSplit {
private List<Functionality> functionalities = new ArrayList<Functionality>();
private List<List<Functionality>> transactionalBundles = new ArrayList<List<Functionality>>();
private Map<Functionality,List<Functionality>> dependencies = new HashMap<Functionality,List<Functionality>>();
public BaseServiceSplit add(Functionality f) {
functionalities.add(f);
return this;
}
public BaseServiceSplit transactionBundle(Functionality... f) {
transactionalBundles.add(new ArrayList<Functionality>(List.of(f)));
return this;
}
private void onewayDependency(Functionality f1, Functionality f2) {
List<Functionality> temp = dependencies.getOrDefault(f1, new ArrayList<Functionality>());
temp.add(f2);
dependencies.put(f1, temp);
}
public BaseServiceSplit dependency(Functionality f1, Functionality f2) {
onewayDependency(f1, f2);
onewayDependency(f2, f1);
return this;
}
private List<Functionality> copy(List<Functionality> lstf) {
return new ArrayList<Functionality>(lstf);
}
private List<Functionality> create(Functionality f) {
return copy(List.of(f));
}
private boolean overlap(List<Functionality> lstf1, List<Functionality> lstf2) {
return lstf1.stream().filter(lstf2::contains).count() > 0;
}
public abstract double valueSplit(int deps, Functionality f);
public List<List<Functionality>> suggestion() {
List<List<Functionality>> res = new ArrayList<List<Functionality>>();
List<Functionality> work = new ArrayList<Functionality>(functionalities);
// start with transactional bundles
for(List<Functionality> b : transactionalBundles) {
boolean already = false;
for(List<Functionality> srv : res) {
if(overlap(b, srv)) {
for(Functionality f : b) {
if(!srv.contains(f)) {
srv.add(f);
work.remove(f);
}
}
already = true;
}
}
if(!already) {
res.add(copy(b));
for(Functionality f : b) {
work.remove(f);
}
}
}
// avoid dependencies to the extent possible
for(Map.Entry<Functionality,List<Functionality>> e : dependencies.entrySet().stream().sorted((me1,me2) -> me2.getValue().size() - me1.getValue().size()).collect(Collectors.toList())) {
Functionality f = e.getKey();
List<Functionality> deps = e.getValue();
// check if still unassigned
if(work.contains(f)) {
// look in existing bundles (transactional + earlier high dependency)
int highdep = -1;
List<Functionality> highsrv = null;
for(List<Functionality> srv : res) {
int ndep = 0;
for(Functionality f2 : srv) {
if(deps.contains(f2)) {
ndep++;
}
}
if(ndep > highdep) {
highdep = ndep;
highsrv = srv;
}
}
if(valueSplit(highdep, f) < 0) {
// belongs in existing bundle (transactional + earlier high dependency)
highsrv.add(f);
work.remove(f);
} else if(deps.size() > 0) {
// belong in new bundle
res.add(create(f));
work.remove(f);
} else {
// leave it
}
}
}
// process rest
List<Functionality> remains = new ArrayList<Functionality>();
while(!work.isEmpty()) {
Functionality f = work.remove(0);
if(valueSplit(0, f) > 0) {
// benefit from being itself => put in new bundle
res.add(create(f));
} else {
// no benefit from being itself => put in remains bundle
remains.add(f);
}
}
if(!remains.isEmpty()) res.add(remains);
return res;
}
}
package archadv;
public class StandardServiceSplit extends BaseServiceSplit {
@Override
public double valueSplit(int deps, Functionality f) {
return (f.isScalable() ? 1.0 : 0.0) + (f.isOptional() ? 0.5 : 0.0) + (f.isUpdateable() ? 1.5 : 0.0) - deps;
}
}
package archadv;
public class Demo {
public static void main(String[] args) {
Functionality regedtcust = new Functionality("Register/edit customer", false, false, false);
Functionality custlog = new Functionality("Customer login", false, false, false);
Functionality vinv = new Functionality("View inventory", false, false, false);
Functionality buy = new Functionality("Buy", false, false, false);
Functionality ship = new Functionality("Ship", false, false, false);
Functionality vrep = new Functionality("View reports", false, true, true);
Functionality emplog = new Functionality("Employee login", false, false, false);
Functionality creedtemp = new Functionality("Create/edit employee", false, true, false);
Functionality mgcust = new Functionality("Manage customers", false, false, false);
Functionality mginv = new Functionality("Manage inventory", false, false, false);
Functionality mgord = new Functionality("Manage orders", false, false, false);
Functionality card = new Functionality("Charge card", false, false, false);
Functionality mgemp = new Functionality("Manage employee", false, false, false);
BaseServiceSplit archdes = new StandardServiceSplit();
archdes.add(regedtcust)
.add(custlog)
.add(vinv)
.add(buy)
.add(ship)
.add(vrep)
.add(emplog)
.add(creedtemp)
.add(mgcust)
.add(mginv)
.add(mgord)
.add(card)
.add(mgemp)
.transactionBundle(buy, mginv, mgord, card)
.transactionBundle(ship, mginv, mgord)
.dependency(regedtcust, mgcust).dependency(custlog, mgcust)
.dependency(vinv, mginv).dependency(vinv, mgord)
.dependency(buy, mginv).dependency(buy, mgord).dependency(buy, card)
.dependency(ship, mginv).dependency(ship, mgord)
.dependency(vrep, mginv).dependency(vrep, mgord)
.dependency(creedtemp, mgemp).dependency(emplog, mgemp);
for(List<Functionality> srv : archdes.suggestion()) {
System.out.println(srv);
}
System.out.println(archdes.suggestion());
}
}
Output:
[Buy, Manage inventory, Manage orders, Charge card, Ship, View inventory] [Manage employee, Employee login, Create/edit employee] [View reports] [Manage customers, Register/edit customer, Customer login]
Same result as with the manual process!!
And let me emphasize: the above code is not an AI coming up with a good architecture - it is architects with good domain knowledge that has done the proper analysis (step 1-4) and the program just apply some simple rules (based on step 5-10) to that input.
| Model | Number services | Network hops for view inventory | Network hops for buy | Network hops for ship | Cross service transaction |
|---|---|---|---|---|---|
| Monolith | 1 | 1 + 2 = 3 | 1 + 3 = 4 | 1 + 2 = 3 | No |
| Mini-services - naive approach | 3 | 1 + 2 + 2 = 5 | 1 + 3 + 3 = 7 | 1 + 2 + 2 = 5 | Yes |
| Micro-services - naive approach | 8 | 1 + 2 + 2 = 5 | 1 + 3 + 3 = 7 | 1 + 2 + 2 = 5 | Yes |
| Nano-services | 13 | 1 + 2 + 2 = 5 | 1 + 3 + 3 = 7 | 1 + 2 + 2 = 5 | Yes |
| Process | 4 | 1 + 2 = 3 | 1 + 3 = 4 | 1 + 2 = 3 | No |
My subjective rating:
The big gap is betwen #2 and #3.
We see that attempts to split up the application without proper analysis can end up being worse than the old monolith.
And to reiterate: there is no guarantee that the process will end up with the best architecture given all knowledge. It is just some basic rules applied to a small subset of all relevant information. But it should be close enough to the best architecture to work as a starting point for discussions between the architects that provided the input.
A typical application will have:
A lot of micro-service architecture are actually only micro-service in back end, but monolith in front end and database.
Splitting up front end can be a particular hard problem. Usually the "single pane of glass" approach are preferred over many separate UI's.
Possible approaches:
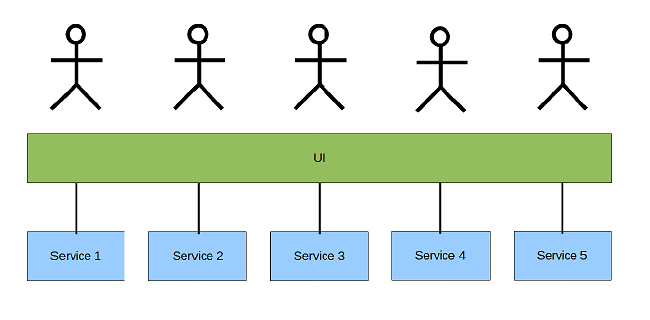
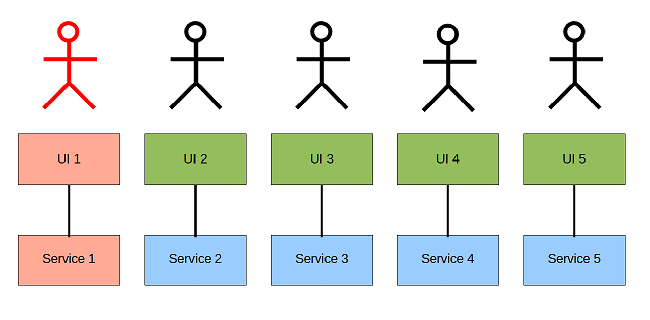
One UI:
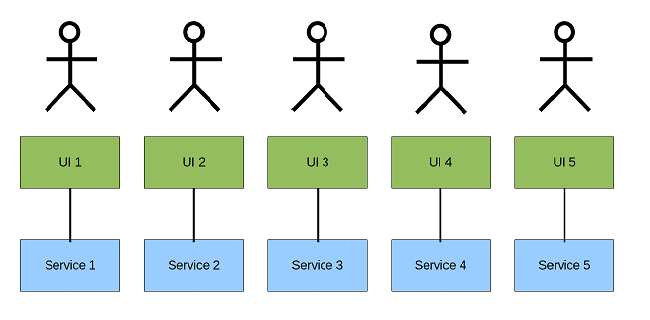
Multiple UI's:
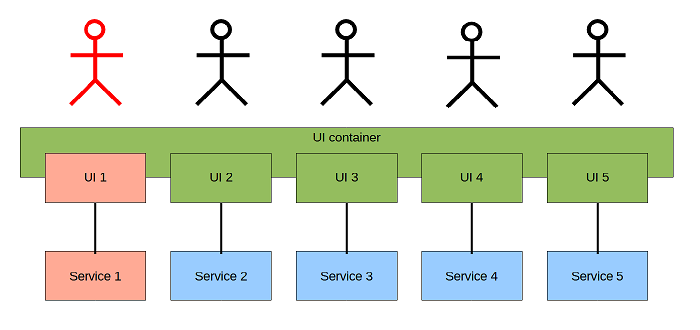
Composite UI:
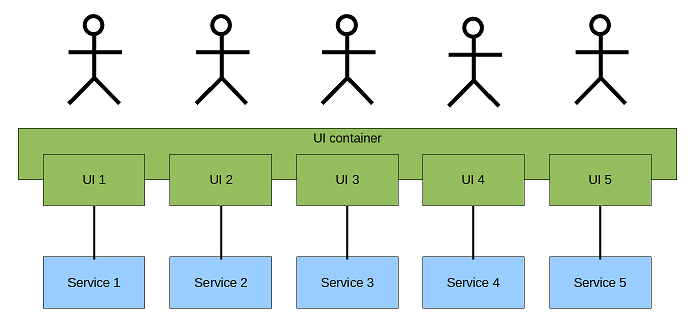
Recommendation: if acceptable go with separate UI's else go with container and plugin model.
The reason is that otherwise it becomes too expensive to test changes to a single service because UI changes spill over to other UI's and use cases:
One UI:
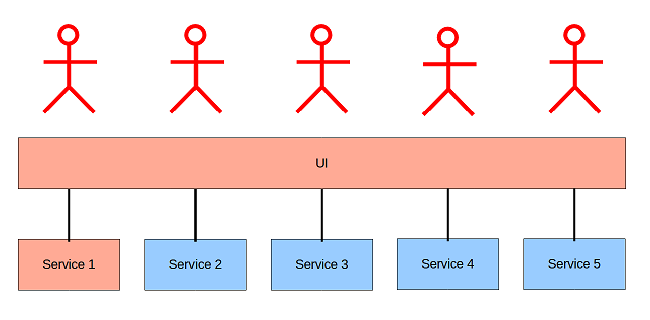
Multiple UI's:
Composite UI:
Databases can also be hard to split up.
For various reasons:
Recommendation: split up the database if possible.
The reason is that shared data create a potential hidden dependency between the back end services. You may not be able to freely change a service independently of other services, because the change may require change to data structures in the database shared with other services.
Databases can be split up both logical as separate databases/schemas and physical as separate database servers.
But logical or physical split is usually more a practical decision due to the fact that most database servers (relational) scale vertical only and are able to control resource allocation to logical databases/schemas.
| Version | Date | Description |
|---|---|---|
| 1.0 | December 9th 2023 | Initial version |
See list of all articles here
Please send comments to Arne Vajhøj