One of the things confusing many people when moving from Windows/*nix to VMS is RMS and what it means for access to files.
This article tries to explain a bit about what RMS is, how it works and what to consider when working on VMS.
The level is introductory and an experienced VMS users would know a lot of this stuff.
The level is just overview. There are a lot more detailed information in the two thick RMS manuals and the signficant material on file usage in every languages reference manual and user guide. But the overview will maybe help understand the detailed information better.
The code examples are trivial. But they do illustrate a point. And besides having the same code in a language one know and a language one doesn't know can be useful to learn the latter language.
RMS is a layer on top of basic VMS IO that provides some additional featutes.
VMS IO sees a disk file as a sequence of disk blocks. RMS sees a file as a set of records. Basically RMS use some meta information from the file header to interpret the disk blocks as records.
VMS IO differs for different device types. Disk IO is different from termimal IO and different from network IO. RMS provide a uniform interface to all of them.
The possible IO stacks are:
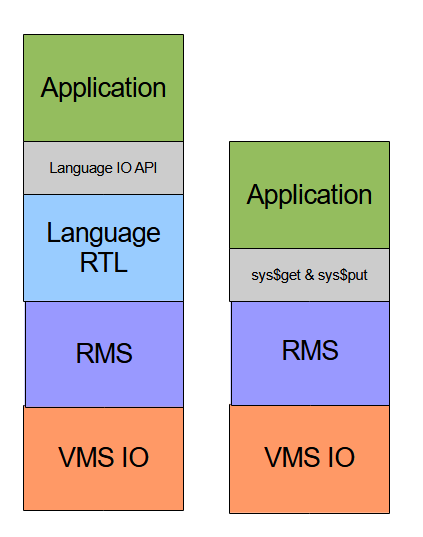
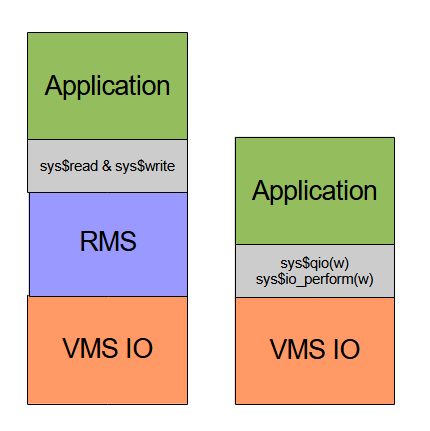
RMS is an integrated part of VMS and runs in executive mode not user mode. So application code and language IO libraries run in user mode, RMS run in executive mode and VMS IO run in kernel mode. This means that RMS internal data structures are protected from application code. It also means a lot of mode changes for IO.
Key concepts in RMS are:
VMS and RMS supports 3 orgainzations:
This confuses the the typical Windows/*nix user because they are used to file system only supporting sequential files and ISAM is provided via a normal library on top of the file system.
VMS and RMS supports 7 record formats:
This confuses the the typical Windows/*nix user because they are used to file system only having one record format for text files and binary files to be considered just a stream of bytes.
Variable length records consist of: 2 bytes with length (little endian format) + bytes of line + 0 or 1 null bytes to pad length to an even number.
So:
A BB CCC
becomes:
| 0x01 | 0x00 | 0x41 | 0x00 | 0x02 | 0x00 | 0x42 | 0x42 | 0x03 | 0x00 | 0x43 | 0x43 | 0x43 | 0x00 |
0x01 0x00 - length 1
0x41 - A
0x00 - pad
0x02 0x00 - length 2
0x42 0x42 - BB
- no pad
0x03 0x00 - length 3
0x43 0x43 0x43 - CCC
0x00 - pad
VFC (Variable Fixedlength Control) records consist of: 2 bytes with length (little endian format) including the length of the control information + N bytes with control information + bytes of line + 0 or 1 null bytes to pad length to an even number. N is usually 2.
A BB CCC
becomes:
| 0x03 | 0x00 | 0x01 | 0x8d | 0x41 | 0x00 | 0x04 | 0x00 | 0x01 | 0x8d | 0x42 | 0x42 | 0x05/td> | 0x00 | 0x01 | 0x8d | 0x43 | 0x43 | 0x43 | 0x00 |
0x03 0x00 - length 2 + 1 = 3
0x01 0x8D - control information
0x41 - A
0x00 - pad
0x04 0x00 - length 2 + 2 = 4
0x01 0x8D - control information
0x42 0x42 - BB
- no pad
0x05 0x00 - length 2 + 3 = 5
0x01 0x8D - control information
0x43 0x43 0x43 - CCC
0x00 - pad
Nobody seems to see a purpose with VFC record format. But DCL create files in VFC record format, so it is used.
Stream records consist of bytes of line + CR + LF. This is traditional DOS/Windows format.
A BB CCC
becomes:
| 0x41 | 0x0C | 0x0A | 0x42 | 0x42 | 0x0C | 0x0A | 0x43 | 0x43 | 0x43 | 0x0C | 0x0A |
0x41 - A 0x0C 0x0A - CR LF 0x42 0x42 - BB 0x0C 0x0A - CR LF 0x43 0x43 0x43 - CCC 0x0C 0x0A - CR LF
Stream LF records consist of bytes of line + LF. This is traditional *nix format.
A BB CCC
becomes:
| 0x41 | 0x0A | 0x42 | 0x42 | 0x0A | 0x43 | 0x43 | 0x43 | 0x0A |
0x41 - A 0x0A - LF 0x42 0x42 - BB 0x0A - LF 0x43 0x43 0x43 - CCC 0x0A - LF
Stream CR records consist of bytes of line + CR. This is traditional Mac format from before MacOS X.
A BB CCC
becomes:
| 0x41 | 0x0C | 0x42 | 0x42 | 0x0C | 0x43 | 0x43 | 0x43 | 0x0C |
0x41 - A 0x0C - CR 0x42 0x42 - BB 0x0C - CR 0x43 0x43 0x43 - CCC 0x0C - CR
Fixed length records consist of bytes of line + 0 or 1 null bytes to pad length to an even number.
A B C
becomes:
| 0x41 | 0x00 | 0x42 | 0x00 | 0x43 | 0x00 |
0x41 - A 0x00 - pad 0x42 - B 0x00 - pad 0x43 - C 0x00 - pad
AA BB CC
becomes:
| 0x41 | 0x41 | 0x42 | 0x42 | 0x43 | 0x43 |
0x41 0x41 - AA 0x42 0x42 - BB 0x43 0x43 - CC
Undefined records mean no records.
It could have been considered natural if binary files on VMS were undefined record format, but traditionally binary files on VMS are fixed length 512 bytes.
The length prefix formats (variable and VFC) are fundamentally different from the separator formats (stream, stream_lf, stream_cr). The length formats allow for all 256 bytes to be present in a record, but reading a file backwards becomes just a good guess.
VMS and RMS supports 3 carriage controls:
Carriage control determines how the file is treated when send to output device - terminal or printer.
Carriage return carriage control is normal behavior - new line in file means new line on output device and a Form Feed (FF) means new page on output device.
Fortran carriage control use the first column in file for control. A space ' ' in first column means ordinary new line. A one '1' in first column means new page. A plus '+' in first column means no new line aka overwrite. A zero '0' in first column means two new lines. This is a very old Fortran convention. And usually it is only files generated by Fortran programs that use Fortran carriage control, but VMS and RMS support sit.
Print carriage control use the content of the control information for VFC files to manage output.
The file attributes include a max record size (MRS).
The meaning depends on the record format. For fixed length records it is the actual length of all records. For other record formats it is just the max length of records and 0 means the limit is the max for the particular record format.
Note that both the file attribute MRS and the length in VAR and VFC records are 16 bit. It is considered potentially signed so that limits the value to 32K.
RMS records can not exceed 32K in length.
That limitation is a hard limitation for RFM FIX (the length is taken as a 16 bit value from the file attributes) and for RFM VAR and VFC (the length is stored on disk in 16 bits).
That limitation is more of a theoretical limitation for RFM STM, STMLF and STMCR. You are not supposed to have records longer than 32K, but most applications doesn't check and doesn't care. Many applications ported from *nix or Windows has to not check to work properly.
For some more info about how the limitation is handled practically jump down here.
That 32K limit may have been considered acceptable in 1977, but today it is a problem. It is too small for todays huge data. And it does not make logical sense for stream formats - and applications being ported from *nix or Windows tend to assume a stream format with no max record size.
VMS Fortran allows for longer logical records (logical records = records seen by application) by using segmented records.
This is a Fortran specific feature added on top of RMS. Programs in other languages does not understand segmented records.
Fortran segmented records consist of: 2 bytes with length (little endian format) including the length of the segment identifier + 2 bytes with segment identified + bytes of line + 0 or 1 null bytes to pad length to an even number.
Segment identifier is:
A BB CCC
becomes:
| 0x03 | 0x00 | 0x03 | 0x00 | 0x41 | 0x00 | 0x04 | 0x00 | 0x03 | 0x00 | 0x42 | 0x42 | 0x05/td> | 0x00 | 0x03 | 0x00 | 0x43 | 0x43 | 0x43 | 0x00 |
0x03 0x00 - length 2 + 1 = 3
0x03 0x00 - only segment
0x41 - A
0x00 - pad
0x04 0x00 - length 2 + 2 = 4
0x03 0x00 - only segment
0x42 0x42 - BB
- no pad
0x05 0x00 - length 2 + 3 = 5
0x03 0x00 - only segment
0x43 0x43 0x43 - CCC
0x00 - pad
The RMS API is build on functions with 3 arguments where 1 argument really contains all the input and output in form of a complex structure called a block.
Blocks include:
Here are a description of some of the most important fields in the blocks. For a complete description see the RMS manual.
The FAB block contains information about file access.
| Field | Content |
|---|---|
| fab$l_fna | address file name |
| fab$b_fns | length file name |
| fab$b_org | orgainsation (FAB$C_SEQ, FAB$C_REL or FAB$C_IDX) for creating new files |
| fab$b_rfm | record format (FAB$C_VAR, FAB$C_VFC, FAB$C_STM, FAB$C_STMLF, FAB$C_STMVR, FAB$C_FIX or FAB$C_UDF) for creating new files |
| fab$b_rat | carriage control (FAB$M_CR or FAB$M_FTN) for creating new files |
| fab$w_mrs | maximum recoord size for creating new files |
| fab$b_fac | file access (FAB$M_GET, FAB$M_PUT, FAB$M_UPD, FAB$M_DEL) |
| fab$l_nam | address NAM block |
| fab$l_xab | address XAB block |
The RAB block contains information about record access.
| Field | Content |
|---|---|
| rab$b_rac | record access (RAB$C_SEQ or RAB$C_KEY) |
| rab$l_fab | address FAB block |
| rab$b_krf | key index (0-9) [for keyed access] |
| rab$l_kbf | address key [for keyed access] |
| rab$b_ksz | length key [for keyed access] |
| rab$l_ubf | address read buffer |
| rab$w_usz | max size read buffer |
| rab$l_rbf | address write buffer |
| rab$w_rsz | actual size read buffer / size write buffer |
The RAB64 block contains information about record access using 64 bit addresses/pointers.
| Field | Content |
|---|---|
| rab64$b_rac | record access (RAB$C_SEQ or RAB$C_KEY) |
| rab64$l_fab | address FAB block |
| rab64$b_krf | key index (0-9) [for keyed access] |
| rab64$pq_kbf | address key [for keyed access] |
| rab64$b_ksz | length key [for keyed access] |
| rab64$pq_ubf | address read buffer |
| rab64$q_usz | max size read buffer |
| rab64$pq_rbf | address write buffer |
| rab64$q_rsz | actual size read buffer / size write buffer |
The NAM block contains information about filenames.
| Field | Content |
|---|---|
| nam$l_rsa | address returned file name |
| nam$b_rss | max size returned file name |
| nam$b_rsl | actual size returned file name |
The NAML block contains information about filenames with support for filenames longer than 255.
| Field | Content |
|---|---|
| naml$l_long_result | address returned file name |
| naml$l_long_result_alloc | max size returned file name |
| naml$l_long_result_size | actual size returned file name |
Various XAB blocks contains extra information.
One of the most relevant is the XABKEY block to define keys in index-sequential files.
| Field | Content |
|---|---|
| xab$b_ref | key index (0-9) |
| xab$b_dtp | data type (XAB$C_IN4, XAB$C_STG or one of the other) |
| xab$w_pos0 | index of key in record |
| xab$b_siz0 | length of key |
RMS supports:
| Functionality | RMS functions |
|---|---|
| open file | SYS$OPEN/SYS$CREATE with FAB block + SYS$CONNECT with RAB block or RAB64 block |
| read record | SYS$GET with RAB block or RAB64 block |
| read block | SYS$READ with RAB block or RAB64 block |
| write record | SYS$PUT with RAB block or RAB64 block |
| write block | SYS$WRITE with RAB block or RAB64 block |
| close file | SYS$DISCONNECT with RAB block or RAB64 block + SYS$CLOSE with FAB block |
| position at record | SYS$FIND with RAB block or RAB64 block |
| update record | SYS$UPDATE with RAB block or RAB64 block |
| delete record | SYS$DELETE with RAB block |
| delete file | SYS$REMOVE with FAB block |
We will see how various IO code read VAR, VFC, STM, STMLF, STMCR and FIX record format files.
First we try actually reading lines.
RMS SYS$GET code in C (any native language could have been used but C is an obvious choice):
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <starlet.h>
#include <rms.h>
int main(int argc, char *argv[])
{
long stat;
struct FAB fab;
struct RAB rab;
char buf[80];
printf("RMS record I/O - %s\n", argv[1]);
fab = cc$rms_fab;
fab.fab$l_fna = argv[1];
fab.fab$b_fns = strlen(argv[1]);
fab.fab$b_fac = FAB$M_GET;
stat = sys$open(&fab, 0, 0);
rab = cc$rms_rab;
rab.rab$l_fab = &fab;
rab.rab$b_rac = RAB$C_SEQ;
stat = sys$connect(&rab, 0 ,0);
for(;;)
{
rab.rab$l_ubf = buf;
rab.rab$w_usz = sizeof(buf);
stat = sys$get(&rab, 0, 0);
if(stat == RMS$_EOF) break;
buf[rab.rab$w_rsz] = 0;
printf("|%s| %d\n", buf, strlen(buf));
}
stat = sys$disconnect(&rab, 0, 0);
stat = sys$close(&fab, 0, 0);
return 0;
}
RMS record I/O - var.txt |A| 1 |BB| 2 |CCC| 3 RMS record I/O - vfc.txt |A| 1 |BB| 2 |CCC| 3 RMS record I/O - stm.txt |A| 1 |BB| 2 |CCC| 3 RMS record I/O - stmlf.txt |A| 1 |BB| 2 |CCC| 3 RMS record I/O - stmcr.txt |A| 1 |BB| 2 |CCC| 3 RMS record I/O - fix1.txt |A| 1 |B| 1 |C| 1 RMS record I/O - fix2.txt |AA| 2 |BB| 2 |CC| 2
Not surprisingly RMS record IO reads RMS logical records fine.
program seq
integer*4 cmdlen, linlen
character*80 cmd, lin
call lib$get_foreign(cmd,,cmdlen)
write(*,*) 'Fortran - ' // cmd(1:cmdlen)
open(unit=1,file=cmd(1:cmdlen),status='old')
100 read(unit=1, fmt=300, end=200) linlen, lin
write(*,*) '|'//lin(1:linlen)//'|', linlen
goto 100
200 close(unit=1)
300 format(Q,A)
end
Fortran - var.txt |A| 1 |BB| 2 |CCC| 3 Fortran - vfc.txt |A| 1 |BB| 2 |CCC| 3 Fortran - stm.txt |A| 1 |BB| 2 |CCC| 3 Fortran - stmlf.txt |A| 1 |BB| 2 |CCC| 3 Fortran - stmcr.txt |A| 1 |BB| 2 |CCC| 3 Fortran - fix1.txt |A| 1 |B| 1 |C| 1 Fortran - fix2.txt |AA| 2 |BB| 2 |CC| 2
[inherit('sys$library:pascal$lib_routines')]
program seq(input,output);
var
cmd : varying [80] of char;
line : varying [80] of char;
f : text;
begin
lib$get_foreign(cmd.body,,cmd.length);
writeln('Pascal - ' + cmd);
open(f, cmd, old);
reset(f);
while not(eof(f)) do begin
readln(f, line);
writeln('|' + line + '|', line.length);
end;
close(f);
end.
Pascal - var.txt |A| 1 |BB| 2 |CCC| 3 Pascal - vfc.txt |A| 1 |BB| 2 |CCC| 3 Pascal - stm.txt |A| 1 |BB| 2 |CCC| 3 Pascal - stmlf.txt |A| 1 |BB| 2 |CCC| 3 Pascal - stmcr.txt |A| 1 |BB| 2 |CCC| 3 Pascal - fix1.txt |A| 1 |B| 1 |C| 1 Pascal - fix2.txt |AA| 2 |BB| 2 |CC| 2
identification division.
program-id.seq.
*
environment division.
input-output section.
file-control.
select in-file assign to "dummy.dat" organization is line sequential.
*
data division.
file section.
fd in-file value of id is infnm.
01 in-record.
03 lin pic x(80).
working-storage section.
01 infnm pic x(80).
01 cmd pic x(80).
01 cmdlen pic s9(8) comp.
01 eof-flag pic x.
01 linlen pic s9(8) comp.
01 linlen2 pic 9(8) display.
*
procedure division.
main-paragraph.
call "lib$get_foreign" using by descriptor cmd, omitted, by reference cmdlen
display "Cobol - " cmd(1:cmdlen)
move cmd(1:cmdlen) to infnm
open input in-file
move 'N' to eof-flag
perform until eof-flag = 'Y'
read in-file
at end move 'Y' to eof-flag
not at end perform display-line-paragraph
end-read
end-perform
close in-file
stop run.
display-line-paragraph.
move 80 to linlen
call "trim" using lin, linlen giving linlen
move linlen to linlen2
display "|" lin(1:linlen) "| " linlen2.
identification division.
program-id.trim.
data division.
working-storage section.
01 actlen pic s9(8) comp.
linkage section.
01 s pic x(256).
01 len pic s9(8) comp.
procedure division using s,len giving actlen.
main-paragraph.
move len to actlen.
perform varying actlen from len by -1 until s(actlen:1) not = " " or actlen = 1
continue
end-perform.
end program trim.
Cobol - var.txt |A| 00000001 |BB| 00000002 |CCC| 00000003 Cobol - vfc.txt |A| 00000001 |BB| 00000002 |CCC| 00000003 Cobol - stm.txt |A| 00000001 |BB| 00000002 |CCC| 00000003 Cobol - stmlf.txt |A| 00000001 |BB| 00000002 |CCC| 00000003 Cobol - stmcr.txt |A| 00000001 |BB| 00000002 |CCC| 00000003 Cobol - fix1.txt |A| 00000001 |B| 00000001 |C| 00000001 Cobol - fix2.txt |AA| 00000002 |BB| 00000002 |CC| 00000002
program seq
option type = explicit
declare string cmd
map (buf) string lin = 80
external sub lib$get_foreign(string)
external string function trim(string)
call lib$get_foreign(cmd)
print "Basic - " + cmd
open "var.txt" for input as file #1, map buf
handler eof_handler
end handler
when error use eof_handler
while 1 = 1
get #1
print "|" + trim(lin) + "|", len(trim(lin))
next
end when
close #1
end program
!
function string trim(string s)
option type = explicit
declare integer ix
ix = len(s)
while ix > 1 and mid$(s, ix, 1) = chr$(0)
ix = ix - 1
next
trim = mid$(s, 1, ix)
end function
Basic - var.txt |A| 1 |BB| 2 |CCC| 3 Basic - vfc.txt |A| 1 |BB| 2 |CCC| 3 Basic - stm.txt |A| 1 |BB| 2 |CCC| 3 Basic - stmlf.txt |A| 1 |BB| 2 |CCC| 3 Basic - stmcr.txt |A| 1 |BB| 2 |CCC| 3 Basic - fix1.txt |A| 1 |BB| 2 |CCC| 3 Basic - fix2.txt |A| 1 |BB| 2 |CCC| 3
$ write sys$output "DCL - ''p1'"
$ open/read f 'p1'
$ loop:
$ read/end=endloop f line
$ write sys$output f$fao("|!AS| !SL", line, f$length(line))
$ goto loop
$ endloop:
$ close f
$ exit
DCL - VAR.TXT |A| 1 |BB| 2 |CCC| 3 DCL - VFC.TXT |A| 1 |BB| 2 |CCC| 3 DCL - STM.TXT |A| 1 |BB| 2 |CCC| 3 DCL - STMLF.TXT |A| 1 |BB| 2 |CCC| 3 DCL - STMCR.TXT |A| 1 |BB| 2 |CCC| 3 DCL - FIX1.TXT |A| 1 |B| 1 |C| 1 DCL - FIX2.TXT |AA| 2 |BB| 2 |CC| 2
The tradfitional VMS languages come with language IO that are natural record oriented and returns RMS records fine.
#include <stdio.h>
#include <string.h>
int main(int argc, char *argv[])
{
printf("C (text, line) - %s\n", argv[1]);
FILE *fp = fopen(argv[1], "r");
char line[80];
while(fgets(line, sizeof(line), fp))
{
int ix = strlen(line) - 1;
if(line[ix] == '\n') line[ix] = 0;
printf("|%s| %d\n", line, strlen(line));
}
fclose(fp);
}
C (text, line) - var.txt |A| 1 |BB| 2 |CCC| 3 C (text, line) - vfc.txt |A| 1 |BB| 2 |CCC| 3 C (text, line) - stm.txt |A| 1 |BB| 2 |CCC| 3 C (text, line) - stmlf.txt |A| 1 |BB| 2 |CCC| 3 C (text, line) - stmcr.txt |A| 1 |BB| 2 |CCC| 3 C (text, line) - fix1.txt |A| 1 |B| 1 |C| 1 C (text, line) - fix2.txt |AA| 2 |BB| 2 |CC| 2
#include <iostream>
#include <fstream>
#include <string>
using namespace std;
int main(int argc, char *argv[])
{
cout << "C++ - " << argv[1] << endl;
ifstream f(argv[1]);
string line;
while(getline(f, line))
{
cout << "|" << line << "| " << line.length() << endl;
}
f.close();
return 0;
}
C++ - var.txt |A| 1 |BB| 2 |CCC| 3 C++ - vfc.txt |A| 1 |BB| 2 |CCC| 3 C++ - stm.txt |A| 1 |BB| 2 |CCC| 3 C++ - stmlf.txt |A| 1 |BB| 2 |CCC| 3 C++ - stmcr.txt |A| 1 |BB| 2 |CCC| 3 C++ - fix1.txt |A| 1 |B| 1 |C| 1 C++ - fix2.txt |AA| 2 |BB| 2 |CC| 2
C and C++ IO are natural stream oriented, but they can read lines. C fgets reads lines but always adds a LF to the end of line no matter whether the record format actually has LF or not. C++ getline read lines like the traditional VMS languages.
The above example works fine for VFC record format, because the test VFC file has the control bytes used by DCL. Non-standard control bytes can cause the control bytes to be included in data read. Note that this is a specific problem for C and languages whose IO is build on top of C IO - the traditional VMS languages does not have this problem.
import java.io.BufferedReader;
import java.io.FileReader;
public class SeqLin {
public static void main(String[] args) throws Exception {
System.out.println("Java (lines) - " + args[0]);
BufferedReader br = new BufferedReader(new FileReader(args[0]));
String line;
while((line = br.readLine()) != null) {
System.out.println("|" + line + "| " + line.length());
}
br.close();
}
}
Java (lines) - var.txt |A| 1 |BB| 2 |CCC| 3 Java (lines) - vfc.txt |A| 1 |BB| 2 |CCC| 3 Java (lines) - stm.txt |A| 1 |BB| 2 |CCC| 3 Java (lines) - stmlf.txt |A| 1 |BB| 2 |CCC| 3 Java (lines) - stmcr.txt |A| 1 |BB| 2 |CCC| 3 Java (lines) - fix1.txt |A| 1 |B| 1 |C| 1 Java (lines) - fix2.txt |AA| 2 |BB| 2 |CC| 2
println("Groovy (lines) - " + args[0])
br = new BufferedReader(new FileReader(args[0]))
while((line = br.readLine()) != null) {
println("|" + line + "| " + line.length())
}
br.close()
Groovy (lines) - VAR.TXT |A| 1 |BB| 2 |CCC| 3 Groovy (lines) - VFC.TXT |A| 1 |BB| 2 |CCC| 3 Groovy (lines) - STM.TXT |A| 1 |BB| 2 |CCC| 3 Groovy (lines) - STMLF.TXT |A| 1 |BB| 2 |CCC| 3 Groovy (lines) - STMCR.TXT |A| 1 |BB| 2 |CCC| 3 Groovy (lines) - FIX1.TXT |A| 1 |B| 1 |C| 1 Groovy (lines) - FIX2.TXT |AA| 2 |BB| 2 |CC| 2
import sys
print('Python (lines) - ' + sys.argv[1])
f = open(sys.argv[1], 'r')
for line in f:
print('|' + line.rstrip() + '| ' + str(len(line.rstrip())))
f.close()
Python (lines) - VAR.TXT |A| 1 |BB| 2 |CCC| 3 Python (lines) - VFC.TXT |A| 1 |BB| 2 |CCC| 3 Python (lines) - STM.TXT |A| 1 |BB| 2 |CCC| 3 Python (lines) - STMLF.TXT |A| 1 |BB| 2 |CCC| 3 Python (lines) - STMCR.TXT |A| 1 |BB| 2 |CCC| 3 Python (lines) - FIX1.TXT |A| 1 |B| 1 |C| 1 Python (lines) - FIX2.TXT |AA| 2 |BB| 2 |CC| 2
The Java runtime is based on C runtime so Java and other JVM languages work like C. In this case without any issues.
import sys
print('Python (lines) - ' + sys.argv[1])
f = open(sys.argv[1], 'r')
for line in f:
print('|' + line.rstrip() + '| ' + str(len(line.rstrip())))
f.close()
Python (lines) - var.txt |A| 1 |BB| 2 |CCC| 3 Python (lines) - vfc.txt |A| 1 |BB| 2 |CCC| 3 Python (lines) - stm.txt |A| 1 |BB| 2 |CCC| 3 Python (lines) - stmlf.txt |A| 1 |BB| 2 |CCC| 3 Python (lines) - stmcr.txt |A| 1 |BB| 2 |CCC| 3 Python (lines) - fix1.txt |A| 1 |B| 1 |C| 1 Python (lines) - fix2.txt |AA| 2 |BB| 2 |CC| 2
<?php
echo "PHP (lines) - ${argv[1]}\n";
$fp = fopen($argv[1], 'r');
while($line = fgets($fp)) {
$line = rtrim($line);
$len = strlen($line);
echo "|$line| $len\n";
}
fclose($fp);
?>
PHP (lines) - var.txt |A| 1 |BB| 2 |CCC| 3 PHP (lines) - vfc.txt |A| 1 |BB| 2 |CCC| 3 PHP (lines) - stm.txt |A| 1 |BB| 2 |CCC| 3 PHP (lines) - stmlf.txt |A| 1 |BB| 2 |CCC| 3 PHP (lines) - stmcr.txt |A| 1 |BB| 2 |CCC| 3 PHP (lines) - fix1.txt |A| 1 |B| 1 |C| 1 PHP (lines) - fix2.txt |AA| 2 |BB| 2 |CC| 2
The script language runtimes are based on C runtime so most script languages work like C. In this case without any issues.
PHP even use the same function names as C although with some slightly more convenient signatures.
Now let us try reading bytes.
RMS is not geared towards reading bytes.
The traditional VMS languages are not geared towards reading bytes.
#include <stdio.h>
int main(int argc, char *argv[])
{
printf("C (text, bytes, ctx=rec) - %s\n", argv[1]);
FILE *fp = fopen(argv[1], "r");
int eol;
int c;
while((c = fgetc(fp)) >= 0)
{
if(c == '\n')
{
printf("\n");
eol = 1;
}
else
{
printf("%02X", c);
eol = 0;
}
}
if(!eol) printf("\n");
fclose(fp);
}
C (text, bytes, ctx=rec) - var.txt 41 4242 434343 C (text, bytes, ctx=rec) - vfc.txt 41 4242 434343 C (text, bytes, ctx=rec) - stm.txt 41 4242 434343 C (text, bytes, ctx=rec) - stmlf.txt 41 4242 434343 C (text, bytes, ctx=rec) - stmcr.txt 41 4242 434343 C (text, bytes, ctx=rec) - fix1.txt 41 42 43 C (text, bytes, ctx=rec) - fix2.txt 4141 4242 4343
#include <stdio.h>
int main(int argc, char *argv[])
{
printf("C (text, bytes, ctx=stm) - %s\n", argv[1]);
FILE *fp = fopen(argv[1], "r", "ctx=stm");
int eol;
int c;
while((c = fgetc(fp)) >= 0)
{
if(c == '\n')
{
printf("\n");
eol = 1;
}
else
{
printf("%02X", c);
eol = 0;
}
}
if(!eol) printf("\n");
fclose(fp);
}
C (text, bytes, ctx=stm) - var.txt 0100410002004242030043434300 C (text, bytes, ctx=stm) - vfc.txt 0300018D41000400018D42420500018D43434300 C (text, bytes, ctx=stm) - stm.txt 410D 42420D 4343430D C (text, bytes, ctx=stm) - stmlf.txt 41 4242 434343 C (text, bytes, ctx=stm) - stmcr.txt 410D42420D4343430D C (text, bytes, ctx=stm) - fix1.txt 410042004300 C (text, bytes, ctx=stm) - fix2.txt 414142424343
#include <stdio.h>
int main(int argc, char *argv[])
{
printf("C (binary, bytes) - %s\n", argv[1]);
FILE *fp = fopen(argv[1], "rb");
int c;
while((c = fgetc(fp)) >= 0)
{
printf("%02X", c);
}
printf("\n");
fclose(fp);
}
C (binary, bytes) - var.txt 414242434343 C (binary, bytes) - vfc.txt 018D41018D4242018D434343 C (binary, bytes) - stm.txt 414242434343 C (binary, bytes) - stmlf.txt 410A42420A4343430A C (binary, bytes) - stmcr.txt 414242434343 C (binary, bytes) - fix1.txt 414243 C (binary, bytes) - fix2.txt 414142424343
Now it starts to be tricky. My interpretaion of the results are:
My recommendation is:
import java.io.FileInputStream;
import java.io.InputStream;
public class SeqByt {
public static void main(String[] args) throws Exception {
System.out.println("Java (bytes) - " + args[0]);
InputStream is = new FileInputStream(args[0]);
int c;
while((c = is.read()) >= 0) {
if(c == '\n')
System.out.printf("\n");
else
System.out.printf("%02X", c);
}
is.close();
}
}
Java (bytes) - var.txt 41 4242 434343 Java (bytes) - vfc.txt 41 4242 434343 Java (bytes) - stm.txt 41 4242 434343 Java (bytes) - stmlf.txt 41 4242 434343 Java (bytes) - stmcr.txt 41 4242 434343 Java (bytes) - fix1.txt 41 42 43 Java (bytes) - fix2.txt 4141 4242 4343
println("Groovy (bytes) - " + args[0])
is = new FileInputStream(args[0])
while((c = is.read()) >= 0) {
if(c == '\n')
printf("\n")
else
printf("%02X", c)
}
is.close()
Groovy (bytes) - VAR.TXT 41 4242 434343 Groovy (bytes) - VFC.TXT 41 4242 434343 Groovy (bytes) - STM.TXT 41 4242 434343 Groovy (bytes) - STMLF.TXT 41 4242 434343 Groovy (bytes) - STMCR.TXT 41 4242 434343 Groovy (bytes) - FIX1.TXT 41 42 43 Groovy (bytes) - FIX2.TXT 4141 4242 4343
import sys
print('Python (bytes) - ' + sys.argv[1])
f = open(sys.argv[1], 'r')
s = ''
while True:
c = f.read(1)
if c == '':
break
if c == '\n':
print(s)
s = ''
else:
s = s + ('%02X' % (ord(c)))
if len(s) > 0:
print(s)
f.close()
Python (bytes) - VAR.TXT 41 4242 434343 Python (bytes) - VFC.TXT 41 4242 434343 Python (bytes) - STM.TXT 41 4242 434343 Python (bytes) - STMLF.TXT 41 4242 434343 Python (bytes) - STMCR.TXT 41 4242 434343 Python (bytes) - FIX1.TXT 41 42 43 Python (bytes) - FIX2.TXT 4141 4242 4343
import sys
print('Python (binary, bytes) - ' + sys.argv[1])
f = open(sys.argv[1], 'rb')
s = ''
while True:
c = f.read(1)
if c == '':
break
s = s + ('%02X' % (ord(c)))
print(s)
f.close()
Python (binary, bytes) - VAR.TXT 410A42420A4343430A Python (binary, bytes) - VFC.TXT 410A42420A4343430A Python (binary, bytes) - STM.TXT 410A42420A4343430A Python (binary, bytes) - STMLF.TXT 410A42420A4343430A Python (binary, bytes) - STMCR.TXT 410A42420A4343430A Python (binary, bytes) - FIX1.TXT 410A420A430A Python (binary, bytes) - FIX2.TXT 41410A42420A43430A
Works like C fgetc with mode text and ctx=rec. Reads the reads the bytes in the logical records plus a LF at line end (whether it exists on disk or not).
import sys
print('Python (bytes) - ' + sys.argv[1])
f = open(sys.argv[1], 'r')
s = ''
while True:
c = f.read(1)
if c == '':
break
if c == '\n':
print(s)
s = ''
else:
s = s + ('%02X' % (ord(c)))
if len(s) > 0:
print(s)
f.close()
Python (bytes) - var.txt 41 4242 434343 Python (bytes) - vfc.txt 41 4242 434343 Python (bytes) - stm.txt 41 4242 434343 Python (bytes) - stmlf.txt 41 4242 434343 Python (bytes) - stmcr.txt 41 4242 434343 Python (bytes) - fix1.txt 41 42 43 Python (bytes) - fix2.txt 4141 4242 4343
Python 2.x:
import sys
print('Python (binary, bytes) - ' + sys.argv[1])
f = open(sys.argv[1], 'rb')
s = ''
while True:
c = f.read(1)
if c == '':
break
s = s + ('%02X' % (ord(c)))
print(s)
f.close()
Python 3.x:
import sys
print('Python (binary, bytes) - ' + sys.argv[1])
f = open(sys.argv[1], 'rb')
s = ''
while True:
c = f.read(1)
if c == b'':
break
s = s + ('%02X' % (ord(c)))
print(s)
f.close()
(the Python 2.x - 3.x difference does not relate to IO)
Python (binary, bytes) - var.txt 0100410002004242030043434300 Python (binary, bytes) - vfc.txt 0300018D41000400018D42420500018D43434300 Python (binary, bytes) - stm.txt 410D0A42420D0A4343430D0A Python (binary, bytes) - stmlf.txt 410A42420A4343430A Python (binary, bytes) - stmcr.txt 410D42420D4343430D Python (binary, bytes) - fix1.txt 410042004300 Python (binary, bytes) - fix2.txt 414142424343
<?php
echo "PHP (bytes) - ${argv[1]}\n";
$fp = fopen($argv[1], 'r');
$eol = false;
while($c = fgetc($fp)) {
$c = ord($c);
if($c == 10) {
echo "\n";
$eol = true;
} else {
echo sprintf('%02X', $c);
$eol = false;
}
}
if(!$eol) echo "\n";
fclose($fp);
?>
PHP (bytes) - var.txt 41 4242 434343 PHP (bytes) - vfc.txt 41 4242 434343 PHP (bytes) - stm.txt 41 4242 434343 PHP (bytes) - stmlf.txt 41 4242 434343 PHP (bytes) - stmcr.txt 41 4242 434343 PHP (bytes) - fix1.txt 41 42 43 PHP (bytes) - fix2.txt 4141 4242 4343
<?php
echo "PHP (binary, bytes) - ${argv[1]}\n";
$fp = fopen($argv[1], 'rb');
while($c = fgetc($fp)) {
$c = ord($c);
echo sprintf('%02X', $c);
}
echo "\n";
fclose($fp);
?>
PHP (binary, bytes) - var.txt 410A42420A4343430A PHP (binary, bytes) - vfc.txt 410A42420A4343430A PHP (binary, bytes) - stm.txt 414242434343 PHP (binary, bytes) - stmlf.txt 410A42420A4343430A PHP (binary, bytes) - stmcr.txt 414242434343 PHP (binary, bytes) - fix1.txt 414243 PHP (binary, bytes) - fix2.txt 414142424343
Mode text works like C fgetc with mode text and ctx=rec. Reads the reads the bytes in the logical records plus a LF at line end (whether it exists on disk or not).
Mode binary is more tricky. Python seems to read actual bytes on disk while PHP either read logical bytes or logical bytes plus LF.
Now let us try reading blocks.
RMS SYS$READ code in C (any native language could have been used but C is an obvious choice):
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <starlet.h>
#include <rms.h>
int main(int argc, char *argv[])
{
long stat;
struct FAB fab;
struct RAB rab;
char buf[512];
printf("RMS block I/O - %s\n", argv[1]);
fab = cc$rms_fab;
fab.fab$l_fna = argv[1];
fab.fab$b_fns = strlen(argv[1]);
fab.fab$b_fac = FAB$M_BIO | FAB$M_GET;
stat = sys$open(&fab, 0, 0);
rab = cc$rms_rab;
rab.rab$l_fab = &fab;
rab.rab$b_rac = RAB$C_SEQ;
stat = sys$connect(&rab, 0 ,0);
rab.rab$l_ubf = buf;
rab.rab$w_usz = sizeof(buf);
stat = sys$read(&rab, 0, 0);
for(int i = 0; i < rab.rab$w_rsz; i++)
{
printf("%02X", buf[i]);
}
printf("\n");
stat = sys$disconnect(&rab, 0, 0);
stat = sys$close(&fab, 0, 0);
return 0;
}
RMS block I/O - var.txt 0100410002004242030043434300 RMS block I/O - vfc.txt 030001FFFFFF8D4100040001FFFFFF8D4242050001FFFFFF8D43434300 RMS block I/O - stm.txt 410D0A42420D0A4343430D0A RMS block I/O - stmlf.txt 410A42420A4343430A RMS block I/O - stmcr.txt 410D42420D4343430D RMS block I/O - fix1.txt 410042004300 RMS block I/O - fix2.txt 414142424343
As expected then RMS block I/O read the actual disk blocks.
#include <stdio.h>
int main(int argc, char *argv[])
{
printf("C (binary, blocks) - %s\n", argv[1]);
FILE *fp = fopen(argv[1], "rb");
char buf[512];
int n = fread(buf, 1, sizeof(buf), fp);
for(int i = 0; i < n; i++)
{
printf("%02X", (unsigned char)buf[i]);
}
printf("\n");
fclose(fp);
}
C (binary, blocks) - var.txt 414242434343 C (binary, blocks) - vfc.txt 018D41018D4242018D434343 C (binary, blocks) - stm.txt 414242434343 C (binary, blocks) - stmlf.txt 410A42420A4343430A C (binary, blocks) - stmcr.txt 414242434343 C (binary, blocks) - fix1.txt 414243 C (binary, blocks) - fix2.txt 414142424343
C fread mode binary works like C fgetc mode binary. For stmlf files: reads the actual bytes on disk. For other files: reads the bytes in the logical records (no LF at line end). For record format VFC include control information.
import java.io.FileInputStream;
import java.io.InputStream;
public class SeqBlk {
public static void main(String[] args) throws Exception {
System.out.println("Java (blocks) - " + args[0]);
InputStream is = new FileInputStream(args[0]);
byte[] buf = new byte[512];
int n;
while((n = is.read(buf)) > 0) {
for(int i = 0; i < n; i++) {
if(buf[i] == '\n')
System.out.printf("\n");
else
System.out.printf("%02X", buf[i]);
}
}
is.close();
}
}
Java (blocks) - var.txt 41 4242 434343 Java (blocks) - vfc.txt 41 4242 434343 Java (blocks) - stm.txt 41 4242 434343 Java (blocks) - stmlf.txt 41 4242 434343 Java (blocks) - stmcr.txt 41 4242 434343 Java (blocks) - fix1.txt 41 42 43 Java (blocks) - fix2.txt 4141 4242 4343
println("Groovy (blocks) - " + args[0])
is = new FileInputStream(args[0])
buf = new byte[512]
while((n = is.read(buf)) > 0) {
for(i in 0..n-1) {
if(buf[i] == '\n')
printf("\n")
else
printf("%02X", buf[i])
}
}
is.close()
Groovy (blocks) - VAR.TXT 41 4242 434343 Groovy (blocks) - VFC.TXT 41 4242 434343 Groovy (blocks) - STM.TXT 41 4242 434343 Groovy (blocks) - STMLF.TXT 41 4242 434343 Groovy (blocks) - STMCR.TXT 41 4242 434343 Groovy (blocks) - FIX1.TXT 41 42 43 Groovy (blocks) - FIX2.TXT 4141 4242 4343
import sys
print('Python (binary, blocks) - ' + sys.argv[1])
f = open(sys.argv[1], 'rb')
buf = f.read(512)
s = ''
for c in buf:
s = s + ('%02X' % (ord(c)))
print(s)
f.close()
Python (binary, blocks) - var.txt 410A42420A4343430A Python (binary, blocks) - vfc.txt 410A42420A4343430A Python (binary, blocks) - stm.txt 410A42420A4343430A Python (binary, blocks) - stmlf.txt 410A42420A4343430A Python (binary, blocks) - stmcr.txt 410A42420A4343430A Python (binary, blocks) - fix1.txt 410A420A430A Python (binary, blocks) - fix2.txt 41410A42420A43430A
Same as reading bytes. Logical bytes plus LF.
Python 2.x:
import sys
print('Python (binary, blocks) - ' + sys.argv[1])
f = open(sys.argv[1], 'rb')
buf = f.read(512)
s = ''
for c in buf:
s = s + ('%02X' % (ord(c)))
print(s)
f.close()
Python 3.x:
import sys
print('Python (binary, blocks) - ' + sys.argv[1])
f = open(sys.argv[1], 'rb')
buf = f.read(512)
s = ''
for c in buf:
s = s + ('%02X' % (c))
print(s)
f.close()
(the Python 2.x - 3.x difference does not relate to IO)
Python (binary, blocks) - var.txt 0100410002004242030043434300 Python (binary, blocks) - vfc.txt 0300018D41000400018D42420500018D43434300 Python (binary, blocks) - stm.txt 410D0A42420D0A4343430D0A Python (binary, blocks) - stmlf.txt 410A42420A4343430A Python (binary, blocks) - stmcr.txt 410D42420D4343430D Python (binary, blocks) - fix1.txt 410042004300 Python (binary, blocks) - fix2.txt 414142424343
<?php
echo "PHP (binary, blocks) - ${argv[1]}\n";
$fp = fopen($argv[1], 'rb');
$buf = fread($fp, 512);
for($i = 0; $i < strlen($buf); $i++) {
echo sprintf('%02X', ord($buf[$i]));
}
echo "\n";
fclose($fp);
?>
PHP (binary, blocks) - var.txt 410A42420A4343430A PHP (binary, blocks) - vfc.txt 410A42420A4343430A PHP (binary, blocks) - stm.txt 414242434343 PHP (binary, blocks) - stmlf.txt 410A42420A4343430A PHP (binary, blocks) - stmcr.txt 414242434343 PHP (binary, blocks) - fix1.txt 414243 PHP (binary, blocks) - fix2.txt 414142424343
Same as reading bytes. Python bytes on disk and PHP a bit confusing.
With direct RMS you always need to specify file attributes.
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <starlet.h>
#include <rms.h>
static void write_one(struct RAB *rabptr, char *buf)
{
long stat;
rabptr->rab$l_rbf = buf;
rabptr->rab$w_rsz = strlen(buf);
stat = sys$put(rabptr, 0, 0);
}
#define FNM "rmsx.txt"
int main(int argc, char *argv[])
{
long stat;
struct FAB fab;
struct RAB rab;
char buf[80];
fab = cc$rms_fab;
fab.fab$l_fna = FNM;
fab.fab$b_fns = strlen(FNM);
fab.fab$b_org = FAB$C_SEQ;
fab.fab$b_rfm = FAB$C_VAR;
fab.fab$b_rat = FAB$M_CR;
fab.fab$b_fac = FAB$M_PUT;
stat = sys$create(&fab, 0, 0);
rab = cc$rms_rab;
rab.rab$l_fab = &fab;
rab.rab$b_rac = RAB$C_SEQ;
stat = sys$connect(&rab, 0 ,0);
write_one(&rab, "A");
write_one(&rab, "BB");
write_one(&rab, "CCC");
stat = sys$disconnect(&rab, 0, 0);
stat = sys$close(&fab, 0, 0);
return 0;
}
Result:
$ cc rms_cre $ link rms_cre $ run rms_cre $ call dump "rmsx.txt" rmsx.txt : ORG=SEQ RFM=VAR RAT=CR MRS=0
Fortran has a default:
program cre
open(unit=1, file='for.txt', status='new')
write(unit=1, fmt='(1x,A)') 'A'
write(unit=1, fmt='(1x,A)') 'BB'
write(unit=1, fmt='(1x,A)') 'CCC'
close(unit=1)
end
Result:
$ for cre $ link cre $ run cre $ call dump "for.txt" for.txt : ORG=SEQ RFM=VAR RAT=FTN MRS=0
But file attributes can be specified explicit in OPEN.
program crex
open(unit=1, file='forx.txt', status='new',
+ recordtype='stream_lf', carriagecontrol='list')
write(unit=1, fmt='(1x,A)') 'A'
write(unit=1, fmt='(1x,A)') 'BB'
write(unit=1, fmt='(1x,A)') 'CCC'
close(unit=1)
end
Result:
$ for crex $ link crex $ run crex $ call dump "forx.txt" forx.txt : ORG=SEQ RFM=STMLF RAT=CR MRS=0
And segmented records:
program seg
open(unit=1, file='seg.dat', status='new',
+ form='unformatted', recordtype='segmented')
write(unit=1) 'A'
write(unit=1) 'BB'
write(unit=1) 'CCC'
close(unit=1)
end
Result:
$ for seg $ link seg $ run seg $ call dump "seg.dat" seg.dat : ORG=SEQ RFM=VAR RAT= MRS=0
Pascal has default.
program cre(input,output);
var
f : text;
begin
open(f, 'pas.txt', new);
rewrite(f);
writeln(f, 'A');
writeln(f, 'BB');
writeln(f, 'CCC');
close(f);
end.
Result:
$ pas cre $ link cre $ run cre $ call dump "pas.txt" pas.txt : ORG=SEQ RFM=VAR RAT=CR MRS=0
But file attributes can be specified explicit in OPEN.
program crex(input,output);
var
f : text;
begin
open(f, 'pasx.txt', new, record_type := stream_lf);
rewrite(f);
writeln(f, 'A');
writeln(f, 'BB');
writeln(f, 'CCC');
close(f);
end.
Result:
$ pas crex $ link crex $ run crex $ call dump "pasx.txt" pasx.txt : ORG=SEQ RFM=STMLF RAT=CR MRS=0
Cobol has default.
identification division.
program-id.cre.
*
environment division.
input-output section.
file-control.
select f assign to "cob.txt" organization is sequential.
*
data division.
file section.
fd f.
01 buf.
03 lin pic x(80).
*
procedure division.
main-paragraph.
open output f
move "A" to lin
write buf
move "BB" to lin
write buf
move "CCC" to lin
write buf
close f
stop run.
Result:
$ cob cre $ link cre $ run cre $ call dump "cob.txt" cob.txt : ORG=SEQ RFM=FIX RAT=CR MRS=80
But there are a few options to impact file attributes in the way the file is opened.
identification division.
program-id.crex.
*
environment division.
input-output section.
file-control.
select f assign to "cobx.txt" organization is line sequential.
*
data division.
file section.
fd f record is varying in size from 0 to 80 depending on linlen.
01 buf.
03 lin pic x(80).
working-storage section.
01 linlen pic 9(9) comp.
*
procedure division.
main-paragraph.
open output f
move "A" to lin
move 1 to linlen
write buf
move "BB" to lin
move 2 to linlen
write buf
move "CCC" to lin
move 3 to linlen
write buf
close f
stop run.
Result:
$ cob crex $ link crex $ run crex $ call dump "cobx.txt" cobx.txt : ORG=SEQ RFM=STMLF RAT=CR MRS=80
Basic got default.
program cre
open "bas.txt" for output as file #1
print #1, "A"
print #1, "BB"
print #1, "CCC"
close #1
end program
Result:
$ bas cre $ link cre $ run cre bas.txt : ORG=SEQ RFM=VAR RAT=CR MRS=132
But file attributes can to some extent be controlled in OPEN.
program cre
open "basx.txt" for output as file #1, organization sequential stream
print #1, "A"
print #1, "BB"
print #1, "CCC"
close #1
end program
Result:
$ bas crex $ link crex $ run crex $ call dump "basx.txt" basx.txt : ORG=SEQ RFM=STM RAT=CR MRS=132
$ open/write f dcl.txt
$ write f "A"
$ write f "BB"
$ write f "CCC"
$ close f
$ exit
Result:
$ @cre $ call dump "dcl.txt" dcl.txt : ORG=SEQ RFM=VFC RAT=PRN MRS=0
$ create/fdl="record; format var" dclx.txt
$ open/append f dclx.txt
$ write f "A"
$ write f "BB"
$ write f "CCC"
$ close f
$ exit
Result:
$ @crex $ call dump "dclx.txt" dclx.txt : ORG=SEQ RFM=VAR RAT=CR MRS=0
C has default:
#include <stdio.h>
int main(int argc, char *argv[])
{
FILE *fp = fopen("c.txt", "w");
fputs("A\n", fp);
fputs("BB\n", fp);
fputs("CCC\n", fp);
fclose(fp);
}
Result:
$ cc cre $ link cre $ run cre $ call dump "c.txt" c.txt : ORG=SEQ RFM=STMLF RAT=CR MRS=0
C fopen and open allow to specify file attributes.
#include <stdio.h>
int main(int argc, char *argv[])
{
FILE *fp = fopen("cx.txt", "w", "rfm=var", "rat=cr");
fputs("A\n", fp);
fputs("BB\n", fp);
fputs("CCC\n", fp);
fclose(fp);
}
Result:
$ cc crex $ link crex $ run crex $ call dump "cx.txt" cx.txt : ORG=SEQ RFM=VAR RAT=CR MRS=0
Java library is C based so it has the same defaults.
import java.io.FileWriter;
import java.io.PrintWriter;
public class Cre {
public static void main(String[] args) throws Exception {
PrintWriter pw = new PrintWriter(new FileWriter(args[0]));
pw.println("A");
pw.println("BB");
pw.println("CCC");
pw.close();
}
}
Result:
$ javac Cre.java $ java "Cre" java.txt $ call dump "java.txt" java.txt : ORG=SEQ RFM=STMLF RAT=CR MRS=0
But defaults can be changed - not by changing the code, but by defining a logical.
Result:
$ define/nolog java$filename_match_list "javax.txt=rfm=var/rat=cr" $ java "Cre" javax.txt $ call dump "javax.txt" javax.txt : ORG=SEQ RFM=VAR RAT=CR MRS=0
Note that the java$filename_match_list logical does supports wildcards, so the following is also valid:
$ define/nolog java$filename_match_list "*.txt=rfm=var/rat=cr"
Other JVM languages like Groovy obviously behave like Java.
pw = new PrintWriter(new FileWriter(args[0]))
pw.println("A")
pw.println("BB")
pw.println("CCC")
pw.close()
Result:
$ groovy Cre.groovy gr.txt $ call dump "gr.txt" gr.txt : ORG=SEQ RFM=STMLF RAT=CR MRS=0
Result:
$ define/nolog java$filename_match_list "GRX.TXT=rfm=var/rat=cr" $ groovy Cre.groovy grx.txt $ call dump "grx.txt" grx.txt : ORG=SEQ RFM=VAR RAT=CR MRS=0
Other JVM languages like Jython obviously behave like Java.
from sys import argv
f = open(argv[1], 'w')
f.write('A\n')
f.write('BB\n')
f.write('CCC\n')
f.close()
Result:
$ jython cre2.py $ call dump "jy.txt" jy.txt : ORG=SEQ RFM=STMLF RAT=CR MRS=0
Result (Jython 2.7 on Java 8 on VMS Itanium and VMS x86-64):
$ define/nolog java$filename_match_list "*JYX.TXT=rfm=var/rat=cr" $ jython cre2.py jyx.txt $ call dump "jyx.txt" jyx.txt : ORG=SEQ RFM=VAR RAT=CR MRS=0
(Jython 2.5 on Java 5 on VMS Alpha gave an error)
Script languages are typical C based and use C default.
f = open('py.txt', 'w')
f.write('A\n')
f.write('BB\n')
f.write('CCC\n')
f.close()
Result:
$ python cre.py $ call dump "py.txt" py.txt : ORG=SEQ RFM=STMLF RAT=CR MRS=0
<?php
$fp = fopen('php.txt', 'w');
fwrite($fp, "A\n");
fwrite($fp, "BB\n");
fwrite($fp, "CCC\n");
fclose($fp);
?>
Result:
$ php cre.php $ call dump "php.txt" php.txt : ORG=SEQ RFM=STMLF RAT=CR MRS=0
What happen if one try to exceed to max record size of 32K?
Short version: nothing good.
Generate some files:
#include <stdio.h>
#include <stdlib.h>
void gen(const char *fnm1, const char *fnm2, int n)
{
FILE *fp1 = fopen(fnm1, "w");
for(int i = 0; i < n; i++) fputc('X', fp1);
fclose(fp1);
FILE *fp2 = fopen(fnm2, "w", "rfm=var");
for(int i = 0; i < n; i++) fputc('X', fp2);
fclose(fp2);
}
int main(int argc, char *argv[])
{
gen(argv[1], argv[2], atoi(argv[3]));
return 0;
}
$ cc gen2
$ link gen2
$ mcr []gen2 stmlf80.txt var80.txt 80
$ mcr []gen2 stmlf32767.txt var32767.txt 32767
$ mcr []gen2 stmlf32768.txt var32768.txt 32768
$ mcr []gen2 stmlf250000.txt var250000.txt 250000
Test files:
#include <stdio.h>
int main(int argc, char *argv[])
{
FILE *fp = fopen(argv[1], "r");
int n = 0;
int c;
while((c = fgetc(fp)) >= 0)
{
n++;
}
printf("%s has %d bytes\n", argv[1], n);
fclose(fp);
return 0;
}
$ cc rd
$ link rd
$ mcr []rd stmlf80.txt
$ mcr []rd stmlf32767.txt
$ mcr []rd stmlf32768.txt
$ mcr []rd stmlf250000.txt
$ mcr []rd var80.txt
$ mcr []rd var32767.txt
$ mcr []rd var32768.txt
$ mcr []rd var250000.txt
$ set noon
$ search stmlf80.txt "nothing" /stat
$ search stmlf32767.txt "nothing" /stat
$ search stmlf32768.txt "nothing" /stat
$ search stmlf250000.txt "nothing" /stat
$ search var80.txt "nothing" /stat
$ search var32767.txt "nothing" /stat
$ search var32768.txt "nothing" /stat
$ search var250000.txt "nothing" /stat
$ copy/log *.txt *.copy
$ diff stmlf80.txt stmlf80.copy
$ diff stmlf32767.txt stmlf32767.copy
$ diff stmlf32768.txt stmlf32768.copy
$ diff stmlf250000.txt stmlf250000.copy
$ diff var80.txt var80.copy
$ diff var32767.txt var32767.copy
$ diff var32768.txt var32768.copy
$ diff var250000.txt var250000.copy
Result:
| RFM | attempted record size | C fgetc | DCL COPY | DCL SEARCH | DCL DIFF |
|---|---|---|---|---|---|
| STMLF | 80 | 80 bytes | OK | 1 record 80 characters |
OK |
| STMLF | 32767 | 32767 bytes | OK | 1 record 32767 characters |
OK |
| STMLF | 32768 | 32768 bytes | OK | 1 record 32768 characters |
record too long error |
| STMLF | 250000 | 250000 bytes | OK | 1 record 32768 characters truncation warning |
record too long error |
| VAR | 80 | 80 bytes | OK | 1 record 80 characters |
OK |
| VAR | 32767 | 32767 bytes | OK | 1 record 32767 characters |
OK |
| VAR | 32768 | 32768 bytes | OK | 2 records 32768 characters |
OK |
| VAR | 250000 | 250000 bytes | OK | 8 records 250000 characters |
OK |
RFM=VAR result in multiple valid records. Which is a consistent state from RMS perspective, but probably not what the author of the code intended.
RFM=STMLF result in the bytes as written. It works fine for C IO (and likely also for C derivative IO like JVM, Python, PHP etc.). It also works fine for block IO. But traditional record IO is likely to give errors.
You have been warned.
RMS supports direct access by record number to fixed length records.
This is possible because:
byte_offset = (record_number - 1) * record_size + 1
#include <stdio.h>
#include <string.h>
#include <starlet.h>
#include <rms.h>
#define FNM "c.fix"
static int eof = 0;
void test_write_one(struct RAB *rabptr, int ix, char *buf)
{
long stat;
rabptr->rab$l_kbf = (char *)&ix;
rabptr->rab$b_ksz = sizeof(ix);
rabptr->rab$l_rbf = buf;
rabptr->rab$w_rsz = strlen(buf);
if(ix > eof)
{
stat = sys$put(rabptr, 0, 0);
eof = ix;
}
else
{
stat = sys$find(rabptr, 0, 0);
stat = sys$update(rabptr, 0, 0);
}
}
void test_write()
{
long stat;
struct FAB fab;
struct RAB rab;
fab = cc$rms_fab;
fab.fab$l_fna = (char *)FNM;
fab.fab$b_fns = strlen(FNM);
fab.fab$b_org = FAB$C_SEQ;
fab.fab$b_rfm = FAB$C_FIX;
fab.fab$w_mrs = 4;
fab.fab$b_fac = FAB$M_PUT | FAB$M_UPD;
stat = sys$create(&fab, 0, 0);
rab = cc$rms_rab;
rab.rab$l_fab = &fab;
rab.rab$b_rac = RAB$C_KEY;
stat = sys$connect(&rab, 0 ,0);
test_write_one(&rab, 3, "CCCC");
test_write_one(&rab, 2, "BBBB");
test_write_one(&rab, 1, "AAAA");
stat = sys$disconnect(&rab, 0, 0);
stat = sys$close(&fab, 0, 0);
}
void test_read_sequential()
{
long stat;
struct FAB fab;
struct RAB rab;
char buf[80];
fab = cc$rms_fab;
fab.fab$l_fna = (char *)FNM;
fab.fab$b_fns = strlen(FNM);
fab.fab$b_fac = FAB$M_GET;
stat = sys$open(&fab, 0, 0);
rab = cc$rms_rab;
rab.rab$l_fab = &fab;
rab.rab$b_rac = RAB$C_SEQ;
stat = sys$connect(&rab, 0 ,0);
for(;;)
{
rab.rab$l_ubf = buf;
rab.rab$w_usz = sizeof(buf);
stat = sys$get(&rab, 0, 0);
if(stat == RMS$_EOF) break;
buf[rab.rab$w_rsz] = 0;
printf("|%s| %d\n", buf, strlen(buf));
}
stat = sys$disconnect(&rab, 0, 0);
stat = sys$close(&fab, 0, 0);
}
void test_read_random_one(struct RAB *rabptr, int ix)
{
long stat;
char buf[80];
rabptr->rab$l_kbf = (char *)&ix;
rabptr->rab$b_ksz = sizeof(ix);
rabptr->rab$l_ubf = buf;
rabptr->rab$w_usz = sizeof(buf);
stat = sys$get(rabptr, 0, 0);
buf[rabptr->rab$w_rsz] = 0;
printf("|%s| %d\n", buf, strlen(buf));
}
void test_read_random()
{
long stat;
struct FAB fab;
struct RAB rab;
fab = cc$rms_fab;
fab.fab$l_fna = (char *)FNM;
fab.fab$b_fns = strlen(FNM);
fab.fab$b_fac = FAB$M_GET;
stat = sys$open(&fab, 0, 0);
rab = cc$rms_rab;
rab.rab$l_fab = &fab;
rab.rab$b_rac = RAB$C_KEY;
stat = sys$connect(&rab, 0 ,0);
test_read_random_one(&rab, 3);
test_read_random_one(&rab, 2);
test_read_random_one(&rab, 1);
stat = sys$disconnect(&rab, 0, 0);
stat = sys$close(&fab, 0, 0);
}
int main(int argc, char *argv[])
{
printf("RMS (C)\n");
test_write();
test_read_sequential();
test_read_random();
return 0;
}
program dir
implicit none
write(*,*) 'Fortran'
call test_write()
call test_read_sequential()
call test_read_random()
end
c
subroutine test_write()
implicit none
open(unit=1, file='for.fix', status='new', form='formatted',
+ organization='sequential', recl=4, recordtype='fixed',
+ access='direct')
call test_write_one(3, 'CCCC')
call test_write_one(2, 'BBBB')
call test_write_one(1, 'AAAA')
close(unit=1)
end
c
subroutine test_write_one(ix, val)
implicit none
integer*4 ix
character*(*) val
write(unit=1, rec=ix) val
end
c
subroutine test_read_sequential()
implicit none
integer*4 buflen
character*80 buf
open(unit=1, file='for.fix', status='old', form='formatted',
+ organization='sequential', recl=4, recordtype='fixed',
+ access='sequential')
100 read(unit=1, fmt='(q,a)', end=200) buflen,buf
write(*,*) '|'//buf(1:buflen)//'|', buflen
goto 100
200 close(unit=1)
end
c
subroutine test_read_random()
implicit none
open(unit=1, file='for.fix', status='old', form='formatted',
+ organization='sequential', recl=4, recordtype='fixed',
+ access='direct')
call test_read_random_one(3)
call test_read_random_one(2)
call test_read_random_one(1)
close(unit=1)
end
c
subroutine test_read_random_one(ix)
implicit none
integer*4 ix
integer*4 buflen
character*80 buf
read(unit=1, fmt='(q,a)', rec=ix) buflen,buf
write(*,*) '|'//buf(1:buflen)//'|', buflen
end
program dir(input,output);
type
fixstr = packed array [1..4] of char;
var
f : file of fixstr;
procedure test_write_one(ix : integer; val : fixstr);
begin
locate(f, ix);
f^ := val;
put(f);
end;
procedure test_write;
begin
open(f, 'pas.fix', new,
organization := sequential, record_length := 4, record_type := fixed,
access_method := direct);
rewrite(f);
test_write_one(3, 'CCCC');
test_write_one(2, 'BBBB');
test_write_one(1, 'AAAA');
close(f);
end;
procedure test_read_sequential;
var
val : fixstr;
begin
open(f, 'pas.fix', old,
organization := sequential, record_length := 4, record_type := fixed,
access_method := sequential);
reset(f);
while not(eof(f)) do begin
val := f^;
writeln('|' + val + '|', length(val));
get(f);
end;
close(f);
end;
procedure test_read_random_one(ix : integer);
var
val : fixstr;
begin
find(f, ix);
val := f^;
writeln('|' + val + '|', length(val));
end;
procedure test_read_random;
begin
open(f, 'pas.fix', old,
organization := sequential, record_length := 4, record_type := fixed,
access_method := direct);
test_read_random_one(3);
test_read_random_one(2);
test_read_random_one(1);
close(f);
end;
begin
writeln('Pascal');
test_write;
test_read_sequential;
test_read_random;
end.
program dir
option type = explicit
external sub test_write()
external sub test_read_sequential()
external sub test_write_random()
print "Basic"
call test_write
call test_read_sequential
call test_read_random
end program
!
sub test_write()
option type = explicit
map(buf) string lin = 4
open "bas.fix" for output as file #1, organization sequential fixed, recordsize 4, map buf
lin = "CCCC"
put #1, record 3
lin = "BBBB"
find #1, record 2
update #1
lin = "AAAA"
find #1, record 1
update #1
close #1
end sub
!
sub test_read_sequential()
option type = explicit
map (buf) string lin = 4
open "bas.fix" for input as file #1, organization sequential fixed, recordsize 4, map buf
handler eof_handler
end handler
when error use eof_handler
while 1 = 1
get #1
print "|" + trm$(lin) + "|", len(trm$(lin))
next
end when
close #1
end sub
!
sub test_read_random()
option type = explicit
map (buf) string lin = 4
open "bas.fix" for input as file #1, organization sequential fixed, recordsize 4, map buf
get #1, record 3
print "|" + trm$(lin) + "|", len(trm$(lin))
get #1, record 2
print "|" + trm$(lin) + "|", len(trm$(lin))
get #1, record 1
print "|" + trm$(lin) + "|", len(trm$(lin))
close #1
end sub
C IO does not support the direct access by record number as the traditional languages do.
But C supports seek by byte offset, which is really the same thing when the record format is fixed.
#include <stdio.h>
#include <string.h>
#define RECSIZ 4
#define FNM "cx.fix"
static long recno(int ix)
{
return (ix - 1) * RECSIZ;
}
static int eof = 0;
static char ZERO[RECSIZ] = { 0 };
void test_write_one(FILE *fp, int ix, char *buf)
{
if(ix > eof) // has to zero out previous records never written before
{
fseek(fp, recno(eof + 1), SEEK_SET);
for(int i = eof + 1; i < ix; i++)
{
fwrite(ZERO, RECSIZ, 1, fp);
}
eof = ix;
}
fseek(fp, recno(ix), SEEK_SET);
fwrite(buf, RECSIZ, 1, fp);
}
void test_write()
{
char mrs[11];
sprintf(mrs, "mrs=%d", RECSIZ);
FILE *fp = fopen(FNM, "wb", "rfm=fix", mrs, "rat=cr");
test_write_one(fp, 3, "CCCC");
test_write_one(fp, 2, "BBBB");
test_write_one(fp, 1, "AAAA");
fclose(fp);
}
void test_read_sequential()
{
FILE *fp = fopen(FNM, "rb");
char buf[RECSIZ+1];
while(fread(buf, RECSIZ, 1, fp))
{
buf[RECSIZ] = 0;
printf("|%s| %d\n", buf, strlen(buf));
}
fclose(fp);
}
void test_read_random_one(FILE *fp, int ix)
{
fseek(fp, recno(ix), SEEK_SET);
char buf[RECSIZ+1];
fread(buf, RECSIZ, 1, fp);
buf[RECSIZ] = 0;
printf("|%s| %d\n", buf, strlen(buf));
}
void test_read_random()
{
FILE *fp = fopen(FNM, "rb");
test_read_random_one(fp, 3);
test_read_random_one(fp, 2);
test_read_random_one(fp, 1);
fclose(fp);
}
int main(int argc, char *argv[])
{
printf("C seek\n");
test_write();
test_read_sequential();
test_read_random();
return 0;
}
Run:
$ cc seek
$ link seek
$ run seek
JVM languages also supports seek - either by some language specific method or via the RandomAccessFile class.
Note that to create a file with record format fixed, then the java$filename_match_list logical need to be used.
import java.io.FileInputStream;
import java.io.InputStream;
import java.io.IOException;
import java.io.RandomAccessFile;
public class Seek {
private static final int RECSIZ = 4;
private static final String FNM = "javax.fix";
private static long recno(int ix) {
return (ix - 1) * RECSIZ;
}
private static int eof = 0;
private static final byte[] ZERO = new byte[RECSIZ];
public static void testWriteOne(RandomAccessFile raf, int ix, String buf) throws IOException {
if(ix > eof + 1) {
raf.seek(recno(eof + 1));
for(int i = eof + 1; i < ix; i++) {
raf.write(ZERO);
}
eof = ix;
}
raf.seek(recno(ix));
raf.write(buf.getBytes());
}
public static void testWrite() throws IOException {
RandomAccessFile raf = new RandomAccessFile(FNM, "rw");
testWriteOne(raf, 3, "CCCC");
testWriteOne(raf, 2, "BBBB");
testWriteOne(raf, 1, "AAAA");
raf.close();
}
public static void testReadSequential() throws IOException {
InputStream is = new FileInputStream(FNM);
byte[] buf = new byte[RECSIZ+1]; // will read a fictive LF
while(is.read(buf) > 0) {
String s = new String(buf, 0, RECSIZ);
System.out.printf("|%s| %d\n", s, s.length());
}
is.close();
}
public static void testReadRandomOne(RandomAccessFile raf, int ix) throws IOException {
raf.seek(recno(ix));
byte[] buf = new byte[RECSIZ];
raf.read(buf);
String s = new String(buf);
System.out.printf("|%s| %d\n", s, s.length());
}
public static void testReadRandom() throws IOException {
RandomAccessFile raf = new RandomAccessFile(FNM, "rw");
testReadRandomOne(raf, 3);
testReadRandomOne(raf, 2);
testReadRandomOne(raf, 1);
raf.close();
}
public static void main(String[] args) throws Exception {
System.out.println("Java seek");
testWrite();
testReadSequential();
testReadRandom();
}
}
Run:
$ javac Seek.java
$ define/nolog java$filename_match_list "javax.fix=rfm=fix/mrs=4/rat=cr"
$ java "Seek"
import groovy.transform.Field
@Field static final int RECSIZ = 4
@Field static final String FNM = "grx.fix"
def recno(ix) {
return (ix - 1) * Seek.RECSIZ
}
@Field static int eof = 0;
@Field static final byte[] ZERO = new byte[RECSIZ];
def testWriteOne(raf, ix, buf) {
if(ix > eof + 1) {
raf.seek(recno(eof + 1))
for(i in (eof + 1)..(ix - 1)) {
raf.write(ZERO)
}
eof = ix
}
raf.seek(recno(ix))
raf.write(buf.getBytes())
}
def testWrite() {
raf = new RandomAccessFile(Seek.FNM, "rw")
testWriteOne(raf, 3, "CCCC")
testWriteOne(raf, 2, "BBBB")
testWriteOne(raf, 1, "AAAA")
raf.close()
}
def testReadSequential() {
is = new FileInputStream(Seek.FNM)
buf = new byte[Seek.RECSIZ+1] // will read a fictive LF
while(is.read(buf) > 0) {
s = new String(buf, 0, Seek.RECSIZ)
printf("|%s| %d\n", s, s.length())
}
is.close()
}
def testReadRandomOne(raf, ix) {
raf.seek(recno(ix))
buf = new byte[Seek.RECSIZ]
raf.read(buf)
s = new String(buf)
printf("|%s| %d\n", s, s.length())
}
def testReadRandom() {
raf = new RandomAccessFile(Seek.FNM, "rw")
testReadRandomOne(raf, 3)
testReadRandomOne(raf, 2)
testReadRandomOne(raf, 1)
raf.close()
}
println("Groovy seek")
testWrite()
testReadSequential()
testReadRandom()
Run:
$ define/nolog java$filename_match_list "*grx.fix=rfm=fix/mrs=4/rat=cr"
$ groovy "Seek.groovy"
RECSIZ = 4
FNM = 'jyx.fix'
def recno(ix):
return (ix - 1) * RECSIZ
eof = 0
ZERO = '\0\0\0\0\n'
def test_write_one(f, ix, buf):
global eof
if ix > eof + 1:
f.seek(recno(eof + 1))
for i in range(ix - eof - 1):
f.write(ZERO)
eof = ix
f.seek(recno(ix))
f.write(buf)
def test_write():
f = open(FNM, 'wb')
test_write_one(f, 3, 'CCCC')
test_write_one(f, 2, 'BBBB')
test_write_one(f, 1, 'AAAA')
f.close()
def test_read_sequential():
f = open(FNM, 'rb')
while True:
buf = f.read(RECSIZ+1) # will read a fictive LF
if len(buf) < RECSIZ:
break
buf = buf[:-1]
print('|%s| %d' % (buf, len(buf)))
f.close()
def test_read_random_one(f, ix):
f.seek(recno(ix))
buf = f.read(RECSIZ)
print('|%s| %d' % (buf, len(buf)))
def test_read_random():
f = open(FNM, 'rb')
test_read_random_one(f, 3)
test_read_random_one(f, 2)
test_read_random_one(f, 1)
f.close()
print('Jython seek')
test_write()
test_read_sequential()
test_read_random()
Run:
$ define/nolog java$filename_match_list "*jyx.fix=rfm=fix/mrs=4/rat=cr"
$ jython seek2.py
Python also got seek.
Note that the file need to be created by DCL to get the right file attributes.
RECSIZ = 4
FNM = 'pyx.fix'
def recno(ix):
return (ix - 1) * RECSIZ
def test_write_one(f, ix, buf):
f.seek(recno(ix))
f.write(buf)
def test_write():
f = open(FNM, 'r+b')
test_write_one(f, 3, 'CCCC')
test_write_one(f, 2, 'BBBB')
test_write_one(f, 1, 'AAAA')
f.close()
def test_read_sequential():
f = open(FNM, 'rb')
while True:
buf = f.read(RECSIZ)
if buf == '':
break
print('|%s| %d' % (buf, len(buf)))
f.close()
def test_read_random_one(f, ix):
f.seek(recno(ix))
buf = f.read(RECSIZ)
print('|%s| %d' % (buf, len(buf)))
def test_read_random():
f = open(FNM, 'rb')
test_read_random_one(f, 3)
test_read_random_one(f, 2)
test_read_random_one(f, 1)
f.close()
print('Python seek')
test_write()
test_read_sequential()
test_read_random()
Run:
$ create/fdl="record; format fixed; size 4" pyx.fix
$ python seek.py
PHP also got seek - very similar to C.
Note that the file need to be created by DCL to get the right file attributes.
<?php
define('RECSIZ', '4');
define('FNM', 'phpx.fix');
function recno($ix) {
return ($ix - 1) * RECSIZ;
}
$eof = 0;
function test_write_one($fp, $ix, $buf) {
if($ix > $eof + 1) {
fseek($fp, $eof + 1);
$ZERO = "\0\0\0\0";
for($i = $eof + 1; $i < $ix; $i++) {
fwrite($fp, $ZERO);
}
$eof = $ix;
}
fseek($fp, recno($ix));
fwrite($fp, $buf);
}
function test_write() {
$fp = fopen(FNM, 'r+b');
test_write_one($fp, 3, 'CCCC');
test_write_one($fp, 2, 'BBBB');
test_write_one($fp, 1, 'AAAA');
fclose($fp);
}
function test_read_sequential() {
$fp = fopen(FNM, 'rb');
while(true) {
$buf = fread($fp, 4);
$len = strlen($buf);
if($len <= 0) {
break;
}
echo "|$buf| $len\r\n";
}
fclose($fp);
}
function test_read_random_one($fp, $ix) {
fseek($fp, recno($ix));
$buf = fread($fp, RECSIZ);
$len = strlen($buf);
echo "|$buf| $len\r\n";
}
function test_read_random() {
$fp = fopen(FNM, 'rb');
test_read_random_one($fp, 3);
test_read_random_one($fp, 2);
test_read_random_one($fp, 1);
fclose($fp);
}
echo "PHP seek\r\n";
test_write();
test_read_sequential();
test_read_random();
?>
Run:
$ create/fdl="record; format fixed; size 4" phpx.fix
$ php seek.php
A relative file is similar to a direct access fixed length record file in the sense that records can be accessed by record number. But relative files offer a few extra features: RMS manage a present/no-present flag and supports RMS record formats so it can do variable length records.
Note that the actual bucket size is the max data length plus what RMS need to provide the extra features. The examples below use a max record size of 504 to allow it including overhead to fit in a 512 byte block.
#include <stdio.h>
#include <string.h>
#include <starlet.h>
#include <rms.h>
#define FNM "c.rel"
void test_write_one(struct RAB *rabptr, int ix, char *buf)
{
long stat;
rabptr->rab$l_kbf = (char *)&ix;
rabptr->rab$b_ksz = sizeof(ix);
rabptr->rab$l_rbf = buf;
rabptr->rab$w_rsz = strlen(buf);
stat = sys$put(rabptr, 0, 0);
}
void test_write()
{
long stat;
struct FAB fab;
struct RAB rab;
fab = cc$rms_fab;
fab.fab$l_fna = (char *)FNM;
fab.fab$b_fns = strlen(FNM);
fab.fab$b_org = FAB$C_REL;
fab.fab$b_rfm = FAB$C_VAR;
fab.fab$w_mrs = 504;
fab.fab$b_fac = FAB$M_PUT;
stat = sys$create(&fab, 0, 0);
rab = cc$rms_rab;
rab.rab$l_fab = &fab;
rab.rab$b_rac = RAB$C_KEY;
stat = sys$connect(&rab, 0 ,0);
test_write_one(&rab, 3, "CCC");
test_write_one(&rab, 2, "BB");
test_write_one(&rab, 1, "A");
stat = sys$disconnect(&rab, 0, 0);
stat = sys$close(&fab, 0, 0);
}
void test_read_sequential()
{
long stat;
struct FAB fab;
struct RAB rab;
char buf[80];
fab = cc$rms_fab;
fab.fab$l_fna = (char *)FNM;
fab.fab$b_fns = strlen(FNM);
fab.fab$b_fac = FAB$M_GET;
stat = sys$open(&fab, 0, 0);
rab = cc$rms_rab;
rab.rab$l_fab = &fab;
rab.rab$b_rac = RAB$C_SEQ;
stat = sys$connect(&rab, 0 ,0);
for(;;)
{
rab.rab$l_ubf = buf;
rab.rab$w_usz = sizeof(buf);
stat = sys$get(&rab, 0, 0);
if(stat == RMS$_EOF) break;
buf[rab.rab$w_rsz] = 0;
printf("|%s| %d\n", buf, strlen(buf));
}
stat = sys$disconnect(&rab, 0, 0);
stat = sys$close(&fab, 0, 0);
}
void test_read_random_one(struct RAB *rabptr, int ix)
{
long stat;
char buf[80];
rabptr->rab$l_kbf = (char *)&ix;
rabptr->rab$b_ksz = sizeof(ix);
rabptr->rab$l_ubf = buf;
rabptr->rab$w_usz = sizeof(buf);
stat = sys$get(rabptr, 0, 0);
buf[rabptr->rab$w_rsz] = 0;
printf("|%s| %d\n", buf, strlen(buf));
}
void test_read_random()
{
long stat;
struct FAB fab;
struct RAB rab;
fab = cc$rms_fab;
fab.fab$l_fna = (char *)FNM;
fab.fab$b_fns = strlen(FNM);
fab.fab$b_fac = FAB$M_GET;
stat = sys$open(&fab, 0, 0);
rab = cc$rms_rab;
rab.rab$l_fab = &fab;
rab.rab$b_rac = RAB$C_KEY;
stat = sys$connect(&rab, 0 ,0);
test_read_random_one(&rab, 3);
test_read_random_one(&rab, 2);
test_read_random_one(&rab, 1);
stat = sys$disconnect(&rab, 0, 0);
stat = sys$close(&fab, 0, 0);
}
int main(int argc, char *argv[])
{
printf("RMS (C)\n");
test_write();
test_read_sequential();
test_read_random();
return 0;
}
program rel
implicit none
write(*,*) 'Fortran'
call test_write()
call test_read_sequential()
call test_read_random()
end
c
subroutine test_write()
implicit none
open(unit=1, file='for.rel', status='new', form='formatted',
+ organization='relative', recl=504, recordtype='variable',
+ access='direct')
call test_write_one(3, 'CCC')
call test_write_one(2, 'BB')
call test_write_one(1, 'A')
close(unit=1)
end
c
subroutine test_write_one(ix, val)
implicit none
integer*4 ix
character*(*) val
write(unit=1, rec=ix) val
end
c
subroutine test_read_sequential()
implicit none
integer*4 buflen
character*80 buf
open(unit=1, file='for.rel', status='old', form='formatted',
+ organization='relative', recl=504, recordtype='variable',
+ access='sequential')
100 read(unit=1, fmt='(q,a)', end=200) buflen,buf
write(*,*) '|'//buf(1:buflen)//'|', buflen
goto 100
200 close(unit=1)
end
c
subroutine test_read_random()
implicit none
open(unit=1, file='for.rel', status='old', form='formatted',
+ organization='relative', recl=504, recordtype='variable',
+ access='direct')
call test_read_random_one(3)
call test_read_random_one(2)
call test_read_random_one(1)
close(unit=1)
end
c
subroutine test_read_random_one(ix)
implicit none
integer*4 ix
integer*4 buflen
character*80 buf
read(unit=1, fmt='(q,a)', rec=ix) buflen,buf
write(*,*) '|'//buf(1:buflen)//'|', buflen
end
program rel(input,output);
type
string = varying [255] of char;
var
f : file of string;
procedure test_write_one(ix : integer; val : string);
begin
locate(f, ix);
f^ := val;
put(f);
end;
procedure test_write;
begin
open(f, 'pas.rel', new,
organization := relative, record_length := 504, record_type := variable,
access_method := direct);
rewrite(f);
test_write_one(3, 'CCC');
test_write_one(2, 'BB');
test_write_one(1, 'A');
close(f);
end;
procedure test_read_sequential;
var
val : string;
begin
open(f, 'pas.rel', old,
organization := relative, record_length := 504, record_type := variable,
access_method := sequential);
reset(f);
while not(eof(f)) do begin
val := f^;
writeln('|' + val + '|', length(val));
get(f);
end;
close(f);
end;
procedure test_read_random_one(ix : integer);
var
val : string;
begin
find(f, ix);
val := f^;
writeln('|' + val + '|', length(val));
end;
procedure test_read_random;
begin
open(f, 'pas.rel', old,
organization := relative, record_length := 504, record_type := variable,
access_method := direct);
test_read_random_one(3);
test_read_random_one(2);
test_read_random_one(1);
close(f);
end;
begin
writeln('Pascal');
test_write;
test_read_sequential;
test_read_random;
end.
identification division.
program-id.rel.
*
environment division.
input-output section.
file-control.
select optional f assign to "cob.rel" organization is relative access mode is dynamic relative key is ix.
*
data division.
file section.
fd f.
01 buf.
03 lin pic x(80).
working-storage section.
01 ix pic 9(8) comp.
01 eof pic x(1).
01 linlen pic s9(8) comp.
01 linlen2 pic 9(8) display.
*
procedure division.
main-paragraph.
display "Cobol"
perform test-write-paragraph
perform test-read-sequential-paragraph
perform test-read-random-paragraph
stop run.
test-write-paragraph.
open i-o f
move 3 to ix
move "CCC" to lin
perform test-write-one-paragraph
move 2 to ix
move "BB" to lin
perform test-write-one-paragraph
move 1 to ix
move "A" to lin
perform test-write-one-paragraph
close f.
test-write-one-paragraph.
write buf
invalid key continue
not invalid key continue
end-write.
test-read-sequential-paragraph.
open i-o f
move "N" to eof
perform until eof = 'Y'
read f next
at end move 'Y' to eof
not at end perform display-line-paragraph
end-read
end-perform
close f.
test-read-random-paragraph.
open i-o f
move 3 to ix
perform test-read-random-one-paragraph
move 2 to ix
perform test-read-random-one-paragraph
move 1 to ix
perform test-read-random-one-paragraph
close f.
test-read-random-one-paragraph.
read f
invalid key continue
not invalid key perform display-line-paragraph
end-read.
display-line-paragraph.
move 80 to linlen
call "trim" using lin, linlen giving linlen
move linlen to linlen2
display "|" lin(1:linlen) "| " linlen2.
identification division.
program-id.trim.
data division.
working-storage section.
01 actlen pic s9(8) comp.
linkage section.
01 s pic x(256).
01 len pic s9(8) comp.
procedure division using s,len giving actlen.
main-paragraph.
move len to actlen.
perform varying actlen from len by -1 until s(actlen:1) not = " " or actlen = 1
continue
end-perform.
end program trim.
program rel
option type = explicit
external sub test_write()
external sub test_read_sequential()
external sub test_write_random()
print "Basic"
call test_write
call test_read_sequential
call test_read_random
end program
!
sub test_write()
option type = explicit
map(buf) string lin = 504
open "bas.rel" for output as file #1, organization relative variable, recordsize 504, map buf
lin = "CCC"
put #1, record 3
lin = "BB"
put #1, record 2
lin = "A"
put #1, record 1
close #1
end sub
!
sub test_read_sequential()
option type = explicit
map (buf) string lin = 504
open "bas.rel" for input as file #1, organization relative variable, recordsize 504, map buf
handler eof_handler
end handler
when error use eof_handler
while 1 = 1
get #1
print "|" + trm$(lin) + "|", len(trm$(lin))
next
end when
close #1
end sub
!
sub test_read_random()
option type = explicit
map (buf) string lin = 504
open "bas.rel" for input as file #1, organization relative variable, recordsize 504, map buf
get #1, record 3
print "|" + trm$(lin) + "|", len(trm$(lin))
get #1, record 2
print "|" + trm$(lin) + "|", len(trm$(lin))
get #1, record 1
print "|" + trm$(lin) + "|", len(trm$(lin))
close #1
end sub
RMS index-sequential files which on other platforms are often known as ISAM files allow lookup of records by key.
In modern terminology it is a Key Value Store NoSQL database.
All index-sequential files has one primary key, but can have additional secondary keys.
The additional seconday keys work like fields with indexes in relational tables: enable fast lookup without need to scan all records.
Let us first look at a single key example. The opposite of the previous integer->string example: a string->integer example.
#include <stdio.h>
#include <string.h>
#include <starlet.h>
#include <rms.h>
#define FNM "c.isq"
struct datarec
{
char id[4];
int val;
};
void test_write_one(struct RAB *rabptr, struct datarec *buf)
{
long stat;
rabptr->rab$l_kbf = buf->id;
rabptr->rab$b_ksz = 4;
rabptr->rab$l_rbf = (char *)buf;
rabptr->rab$w_rsz = sizeof(struct datarec);
stat = sys$put(rabptr, 0, 0);
}
void test_write()
{
long stat;
struct FAB fab;
struct RAB rab;
struct XABKEY xab;
struct datarec buf;
fab = cc$rms_fab;
fab.fab$l_fna = (char *)FNM;
fab.fab$b_fns = strlen(FNM);
fab.fab$b_org = FAB$C_IDX;
fab.fab$b_rfm = FAB$C_FIX;
fab.fab$w_mrs = 8;
fab.fab$b_fac = FAB$M_PUT;
fab.fab$l_xab = (char *)&xab;
xab = cc$rms_xabkey;
xab.xab$b_dtp = XAB$C_STG;
xab.xab$w_pos0 = 0;
xab.xab$b_ref = 0;
xab.xab$b_siz0 = 4;
stat = sys$create(&fab, 0, 0);
rab = cc$rms_rab;
rab.rab$l_fab = &fab;
rab.rab$b_rac = RAB$C_KEY;
stat = sys$connect(&rab, 0 ,0);
memcpy(buf.id, "CCCC", 4);
buf.val = 3;
test_write_one(&rab, &buf);
memcpy(buf.id, "BBBB", 4);
buf.val = 2;
test_write_one(&rab, &buf);
memcpy(buf.id, "AAAA", 4);
buf.val = 1;
test_write_one(&rab, &buf);
stat = sys$disconnect(&rab, 0, 0);
stat = sys$close(&fab, 0, 0);
}
void test_read_sequential()
{
long stat;
struct FAB fab;
struct RAB rab;
struct datarec buf;
fab = cc$rms_fab;
fab.fab$l_fna = (char *)FNM;
fab.fab$b_fns = strlen(FNM);
fab.fab$b_fac = FAB$M_GET;
stat = sys$open(&fab, 0, 0);
rab = cc$rms_rab;
rab.rab$l_fab = &fab;
rab.rab$b_rac = RAB$C_SEQ;
stat = sys$connect(&rab, 0 ,0);
for(;;)
{
rab.rab$l_ubf = (char *)&buf;
rab.rab$w_usz = sizeof(struct datarec);
stat = sys$get(&rab, 0, 0);
if(stat == RMS$_EOF) break;
printf("%4s -> %d\n", buf.id, buf.val);
}
stat = sys$disconnect(&rab, 0, 0);
stat = sys$close(&fab, 0, 0);
}
void test_read_random_one(struct RAB *rabptr, char *id)
{
long stat;
struct datarec buf;
rabptr->rab$l_kbf = id;
rabptr->rab$b_ksz = 4;
rabptr->rab$l_ubf = (char *)&buf;
rabptr->rab$w_usz = sizeof(struct datarec);
stat = sys$get(rabptr, 0, 0);
printf("%4s -> %d\n", buf.id, buf.val);
}
void test_read_random()
{
long stat;
struct FAB fab;
struct RAB rab;
fab = cc$rms_fab;
fab.fab$l_fna = (char *)FNM;
fab.fab$b_fns = strlen(FNM);
fab.fab$b_fac = FAB$M_GET;
stat = sys$open(&fab, 0, 0);
rab = cc$rms_rab;
rab.rab$l_fab = &fab;
rab.rab$b_rac = RAB$C_KEY;
stat = sys$connect(&rab, 0 ,0);
test_read_random_one(&rab, "CCCC");
test_read_random_one(&rab, "BBBB");
test_read_random_one(&rab, "AAAA");
stat = sys$disconnect(&rab, 0, 0);
stat = sys$close(&fab, 0, 0);
}
int main(int argc, char *argv[])
{
printf("RMS (C)\n");
test_write();
test_read_sequential();
test_read_random();
return 0;
}
program isq
implicit none
write(*,*) 'Fortran'
call test_write
call test_read_sequential
call test_read_random
end
c
subroutine test_write
implicit none
open(unit=1, file='for.isq', status='new',
+ recordtype='fixed', form='unformatted', recl=8,
+ organization='indexed', access='keyed',
+ key=(1:4:character))
call test_write_one('CCCC', 3)
call test_write_one('BBBB', 2)
call test_write_one('AAAA', 1)
close(unit=1)
end
c
subroutine test_write_one(id, val)
implicit none
character*4 id
integer*4 val
structure /datarec/
character*4 id
integer*4 val
end structure
record /datarec/buf
buf.id = id
buf.val = val
write(unit=1) buf
end
c
subroutine test_read_sequential
implicit none
structure /datarec/
character*4 id
integer*4 val
end structure
record /datarec/buf
open(unit=1, file='for.isq', status='old',
+ recordtype='fixed', form='unformatted', recl=8,
+ organization='indexed', access='sequential',
+ key=(1:4:character))
100 read(unit=1, end=200) buf
write(*,*) buf.id, ' -> ', buf.val
goto 100
200 close(unit=1)
end
c
subroutine test_read_random
implicit none
open(unit=1, file='for.isq', status='old',
+ recordtype='fixed', form='unformatted', recl=8,
+ organization='indexed', access='keyed',
+ key=(1:4:character))
call test_read_random_one('CCCC')
call test_read_random_one('BBBB')
call test_read_random_one('AAAA')
close(unit=1)
end
c
subroutine test_read_random_one(id)
implicit none
character*4 id
structure /datarec/
character*4 id
integer*4 val
end structure
record /datarec/buf
read(unit=1, keyeq=id) buf
write(*,*) buf.id, ' -> ', buf.val
end
program isq(input,output);
type
idstr = packed array [1..4] of char;
datarec = record
id : [key(0)] idstr;
val : integer;
end;
var
db : file of datarec;
procedure test_write_one(id : idstr; val : integer);
var
buf : datarec;
begin
buf.id := id;
buf.val := val;
db^ := buf;
put(db);
end;
procedure test_write;
begin
open(db, 'pas.isq', new, organization := indexed, access_method := keyed);
test_write_one('CCCC', 3);
test_write_one('BBBB', 2);
test_write_one('AAAA', 1);
close(db);
end;
procedure test_read_sequential;
var
buf : datarec;
begin
open(db, 'pas.isq', old, organization := indexed, access_method := sequential);
reset(db);
while not(eof(db)) do begin
buf := db^;
writeln(buf.id, ' -> ', buf.val);
get(db);
end;
close(db);
end;
procedure test_read_random_one(id : idstr);
var
buf : datarec;
begin
findk(db, 0, id);
buf := db^;
writeln(buf.id, ' -> ', buf.val);
end;
procedure test_read_random;
begin
open(db, 'pas.isq', old, organization := indexed, access_method := keyed);
test_read_random_one('CCCC');
test_read_random_one('BBBB');
test_read_random_one('AAAA');
close(db);
end;
begin
writeln('Pascal');
test_write;
test_read_sequential;
test_read_random;
end.
identification division.
program-id.isq.
*
environment division.
input-output section.
file-control.
select optional dbf assign to "cob.isq" organization is indexed access mode is dynamic record key is id.
*
data division.
file section.
fd dbf.
01 buf.
03 id pic x(4).
03 val pic 9(8) comp.
working-storage section.
01 val2 pic 9(8) display.
01 eof pic x(1).
*
procedure division.
main-paragraph.
display "Cobol"
perform test-write-paragraph
perform test-read-sequential-paragraph
perform test-read-random-paragraph
stop run.
test-write-paragraph.
open output dbf
move "CCCC" to id
move 3 to val
perform test-write-one-paragraph
move "BBBB" to id
move 2 to val
perform test-write-one-paragraph
move "AAAA" to id
move 1 to val
perform test-write-one-paragraph
close dbf.
test-write-one-paragraph.
write buf
invalid key display "Invalid key " id
not invalid key continue
end-write.
test-read-sequential-paragraph.
open input dbf
move "N" to eof
perform until eof = "Y"
read dbf next
at end move "Y" to eof
not at end perform display-buf-paragraph
end-read
end-perform
close dbf.
test-read-random-paragraph.
open input dbf
move "CCCC" to id
perform test-read-random-one-paragraph
move "BBBB" to id
perform test-read-random-one-paragraph
move "AAAA" to id
perform test-read-random-one-paragraph
close dbf.
test-read-random-one-paragraph.
read dbf
invalid key display "Key not found " id
not invalid key perform display-buf-paragraph
end-read.
display-buf-paragraph.
move val to val2
display id " -> " val2.
program isq
option type = explicit
external sub test_write
external sub test_read_sequential
external sub test_read_random
print "Basic"
call test_write
call test_read_sequential
call test_read_random
end program
!
sub test_write
option type = explicit
record datarec
string id = 4
integer ival
end record
map (bufmap) datarec buf
external sub test_write_one(string, integer)
open "bas.isq" for output as file #1, indexed fixed, recordtype none, map bufmap, primary key buf::id
call test_write_one("CCCC", 3)
call test_write_one("BBBB", 2)
call test_write_one("AAAA", 1)
close #1
end sub
!
sub test_write_one(string id, integer ival)
option type = explicit
record datarec
string id = 4
integer ival
end record
map (bufmap) datarec buf
buf::id = id
buf::ival = ival
put #1
end sub
!
sub test_read_sequential
option type = explicit
record datarec
string id = 4
integer ival
end record
map (bufmap) datarec buf
open "bas.isq" for input as file #1, indexed fixed, recordtype none, map bufmap, primary key buf::id
handler eof_handler
end handler
when error use eof_handler
while 1 = 1
get #1
print buf::id, " -> ", buf::ival
next
end when
close #1
end sub
!
sub test_read_random
option type = explicit
record datarec
string id = 4
integer ival
end record
map (bufmap) datarec buf
external sub test_read_random_one(string)
open "bas.isq" for input as file #1, indexed fixed, recordtype none, map bufmap, primary key buf::id
call test_read_random_one("CCCC")
call test_read_random_one("BBBB")
call test_read_random_one("AAAA")
close #1
end sub
!
sub test_read_random_one(string id)
option type = explicit
record datarec
string id = 4
integer ival
end record
map (bufmap) datarec buf
get #1, key #0 eq id
print buf::id, " -> ", buf::ival
end sub
$ write sys$output "DCL"
$ call test_write
$ call test_read_sequential
$ call test_read_random
$ exit
$!
$ test_write: subroutine
$ create/fdl=sys$input dcl.isq
FILE
ORGANIZATION indexed
RECORD
FORMAT fixed
SIZE 8
KEY 0
SEG0_LENGTH 4
SEG0_POSITION 0
TYPE string
$
$ open/read/write db dcl.isq
$ call test_write_one "CCCC" 3
$ call test_write_one "BBBB" 2
$ call test_write_one "AAAA" 1
$ close db
$ return
$ endsubroutine
$!
$ test_write_one: subroutine
$ id = p1
$ val[0,32] = f$integer(p2)
$ buf = id + val
$ write db buf
$ return
$ endsuboutine
$!
$ test_read_sequential: subroutine
$ open/read db dcl.isq
$ loop:
$ read/end=endloop db buf
$ id = f$extract(0, 4, buf)
$ val = f$cvsi(0, 32, f$extract(4, 4, buf))
$ write sys$output f$fao("!AS -> !SL", id, val)
$ goto loop
$ endloop:
$ close db
$ return
$ endsubroutine
$!
$ test_read_random: subroutine
$ open/read db dcl.isq
$ call test_read_random_one "CCCC"
$ call test_read_random_one "BBBB"
$ call test_read_random_one "AAAA"
$ close db
$ return
$ endsubroutine
$!
$ test_read_random_one: subroutine
$ read/index=0/key="''p1'" db buf
$ id = f$extract(0, 4, buf)
$ val = f$cvsi(0, 32, f$extract(4, 4, buf))
$ write sys$output f$fao("!AS -> !SL", id, val)
$ return
$ endsubroutine
Non-native languages cannot read index-sequential files without a native library.
For JVM languages I will use my ISAM library.
import dk.vajhoej.isam.KeyField;
import dk.vajhoej.record.FieldType;
import dk.vajhoej.record.Struct;
import dk.vajhoej.record.StructField;
@Struct
public class DataRec {
@KeyField(n=0)
@StructField(n=0, type=FieldType.FIXSTR, length=4)
private String id;
@StructField(n=1, type=FieldType.INT4)
private int val;
public DataRec() {
this(" ", 0);
}
public DataRec(String id, int val) {
this.id = id;
this.val = val;
}
public String getId() {
return id;
}
public int getVal() {
return val;
}
}
import dk.vajhoej.isam.IsamException;
import dk.vajhoej.isam.IsamResult;
import dk.vajhoej.isam.IsamSource;
import dk.vajhoej.isam.Key0;
import dk.vajhoej.isam.local.LocalIsamSource;
import dk.vajhoej.record.RecordException;
public class Isq {
public static void testWriteOne(IsamSource db, String id, int val) throws IsamException, RecordException {
db.create(new DataRec(id, val));
}
public static void testWrite() throws IsamException, RecordException {
IsamSource db = new LocalIsamSource("java.isq", "dk.vajhoej.vms.rms.IndexSequential", false);
testWriteOne(db, "CCCC", 3);
testWriteOne(db, "BBBB", 2);
testWriteOne(db, "AAAA", 1);
db.close();
}
public static void testReadSequential() throws IsamException, RecordException {
IsamSource db = new LocalIsamSource("java.isq", "dk.vajhoej.vms.rms.IndexSequential", true);
IsamResult<DataRec> it = db.readGE(DataRec.class, new Key0<String>(" "));
while(it.read()) {
DataRec buf = it.current();
System.out.printf("%s -> %d\n", buf.getId(), buf.getVal());
}
db.close();
}
public static void testReadRandomOne(IsamSource db, String id) throws IsamException, RecordException {
DataRec buf = db.read(DataRec.class, new Key0<String>(id));
System.out.printf("%s -> %d\n", buf.getId(), buf.getVal());
}
public static void testReadRandom() throws IsamException, RecordException {
IsamSource db = new LocalIsamSource("java.isq", "dk.vajhoej.vms.rms.IndexSequential", true);
testReadRandomOne(db, "CCCC");
testReadRandomOne(db, "BBBB");
testReadRandomOne(db, "AAAA");
db.close();
}
public static void main(String[] args) throws Exception {
System.out.println("Java");
testWrite();
testReadSequential();
testReadRandom();
}
}
import dk.vajhoej.isam.KeyField;
import dk.vajhoej.record.FieldType;
import dk.vajhoej.record.Struct;
import dk.vajhoej.record.StructField;
@Struct
public class DataRec {
@KeyField(n=0)
@StructField(n=0, type=FieldType.FIXSTR, length=4)
private String id;
@StructField(n=1, type=FieldType.INT4)
private int val;
public DataRec() {
this(" ", 0);
}
public DataRec(String id, int val) {
this.id = id;
this.val = val;
}
public String getId() {
return id;
}
public int getVal() {
return val;
}
}
from dk.vajhoej.isam import Key0
from dk.vajhoej.isam.local import LocalIsamSource
import DataRec
def test_write_one(db, id, val):
db.create(DataRec(id, val))
def test_write():
db = LocalIsamSource('jy.isq', 'dk.vajhoej.vms.rms.IndexSequential', False)
test_write_one(db, 'CCCC', 3)
test_write_one(db, 'BBBB', 2)
test_write_one(db, 'AAAA', 1)
db.close()
def test_read_sequential():
db = LocalIsamSource('jy.isq', 'dk.vajhoej.vms.rms.IndexSequential', True)
it = db.readGE(DataRec, Key0(' '))
while it.read():
res = it.current()
print('%s -> %d' % (res.id, res.val))
db.close()
def test_read_random_one(db, id):
res = db.read(DataRec, Key0(id))
print('%s -> %d' % (res.id, res.val))
def test_read_random():
db = LocalIsamSource('jy.isq', 'dk.vajhoej.vms.rms.IndexSequential', True)
test_read_random_one(db, 'CCCC')
test_read_random_one(db, 'BBBB')
test_read_random_one(db, 'AAAA')
db.close()
print('Jython')
test_write()
test_read_sequential()
test_read_random()
JFP VMS Python comes with a vms.rms.IndexedFile class to access index-sequential files.
from construct import *
from vms.rms.IndexedFile import IndexedFile
class DataRec:
def __init__(self, id, val):
self.id = id
self.val = val
class DataFile(IndexedFile):
def __init__(self, fnm):
IndexedFile.__init__(self, fnm, Struct('data_rec', String('id', 4), SNInt32('val')))
def primary_keynum(self):
return 0
def pack_key(self, keynum, keyval):
return keyval
def keyval(self, rec, keynum):
return rec.id
def test_write_one(db, id, val):
db.put(DataRec(id, val))
def test_write():
db = DataFile('py.isq')
test_write_one(db, 'CCCC', 3)
test_write_one(db, 'BBBB', 2)
test_write_one(db, 'AAAA', 1)
def test_read_sequential():
db = DataFile('py.isq')
for rec in db:
res = DataRec(rec.id, rec.val)
print('%s -> %d' % (res.id, res.val))
def test_read_random_one(db, id):
rec = db.fetch(0, id)
res = DataRec(rec.id, rec.val)
print('%s -> %d' % (res.id, res.val))
def test_read_random():
db = DataFile('py.isq')
test_read_random_one(db, 'CCCC')
test_read_random_one(db, 'BBBB')
test_read_random_one(db, 'AAAA')
print('Python')
test_write()
test_read_sequential()
test_read_random()
Next let us look at a 3 key example.
Load test data:
$ convert/fdl=sys$input emp.dat emp.isq
FILE
ORGANIZATION indexed
RECORD
FORMAT fixed
SIZE 24
KEY 0
SEG0_LENGTH 4
SEG0_POSITION 0
TYPE string
KEY 1
SEG0_LENGTH 10
SEG0_POSITION 4
TYPE string
KEY 2
SEG0_LENGTH 10
SEG0_POSITION 14
TYPE string
$
$ exit
0001Alan A Manager
0002Brian B Engineer
0003Chris C Sales Rep
0004Dave D Intern
#include <stdio.h>
#include <string.h>
#include <starlet.h>
#include <rms.h>
struct employee
{
char no[4];
char name[10];
char role[10];
};
#define FNM "emp.isq"
int main()
{
long stat;
struct FAB fab;
struct RAB rab;
struct employee res;
char *no, *name, *role;
printf("RMS (C)\n");
fab = cc$rms_fab;
fab.fab$l_fna = (char *)FNM;
fab.fab$b_fns = strlen(FNM);
fab.fab$b_fac = FAB$M_GET;
stat = sys$open(&fab, 0, 0);
rab = cc$rms_rab;
rab.rab$l_fab = &fab;
rab.rab$b_rac = RAB$C_KEY;
stat = sys$connect(&rab, 0 ,0);
no = "0002";
rab.rab$b_krf = 0;
rab.rab$l_kbf = no;
rab.rab$b_ksz = strlen(no);
rab.rab$l_ubf = (char *)&res;
rab.rab$w_usz = sizeof(struct employee);
stat = sys$get(&rab, 0, 0);
if(stat == RMS$_NORMAL)
{
printf("By no : %4.4s %10.10s %10.10s\n", res.no, res.name, res.role);
}
else
{
printf("Key not found : no\n");
}
name = "Brian B ";
rab.rab$b_krf = 1;
rab.rab$l_kbf = name;
rab.rab$b_ksz = strlen(name);
rab.rab$l_ubf = (char *)&res;
rab.rab$w_usz = sizeof(struct employee);
stat = sys$get(&rab, 0, 0);
if(stat == RMS$_NORMAL)
{
printf("By name : %4.4s %10.10s %10.10s\n", res.no, res.name, res.role);
}
else
{
printf("Key not found : name\n");
}
role = "Engineer ";
rab.rab$b_krf = 2;
rab.rab$l_kbf = role;
rab.rab$b_ksz = strlen(role);
rab.rab$l_ubf = (char *)&res;
rab.rab$w_usz = sizeof(struct employee);
stat = sys$get(&rab, 0, 0);
if(stat == RMS$_NORMAL)
{
printf("By role : %4.4s %10.10s %10.10s\n", res.no, res.name, res.role);
}
else
{
printf("Key not found : role\n");
}
stat = sys$disconnect(&rab, 0, 0);
stat = sys$close(&fab, 0, 0);
return 0;
}
program emp
implicit none
structure /employee/
character*4 no
character*10 name
character*10 role
end structure
record /employee/res
write(*,*) 'Fortran'
open(unit=1, file='emp.isq', status='old',
+ recordtype='fixed', form='unformatted', recl=6, ! note RECL is in longwords not bytes
+ organization='indexed', access='keyed',
+ key=(1:4:character))
read(unit=1, keyid=0, keyeq='0002', err=100) res
write(*,*) 'By no : ', res.no, ' ', res.name, ' ', res.role
goto 200
100 write(*,*) 'Key not found : no'
200 read(unit=1, keyid=1, keyeq='Brian B ', err=300) res
write(*,*) 'By name : ', res.no, ' ', res.name, ' ', res.role
goto 400
300 write(*,*) 'Key not found : name'
400 read(unit=1, keyid=2, keyeq='Engineer ', err=500) res
write(*,*) 'By role : ', res.no, ' ', res.name, ' ', res.role
goto 600
500 write(*,*) 'Key not found : role'
600 close(unit=1)
end
program emp(input,output);
type
employee = record
no : [key(0)] packed array [1..4] of char;
name : [key(1,duplicates)] packed array [1..10] of char;
role : [key(2,duplicates)] packed array [1..10] of char;
end;
var
empdb : file of employee;
res : employee;
begin
writeln('Pascal');
open(empdb, 'emp.isq', old, organization := indexed, access_method := keyed);
findk(empdb, 0, '0002');
if not(ufb(empdb)) then begin
res := empdb^;
writeln('By no : ', res.no, ' ', res.name, ' ', res.role);
end else begin
writeln('Key not found : no');
end;
findk(empdb, 1, 'Brian B ');
if not(ufb(empdb)) then begin
res := empdb^;
writeln('By name : ', res.no, ' ', res.name, ' ', res.role);
end else begin
writeln('Key not found : name');
end;
findk(empdb, 2, 'Engineer ');
if not(ufb(empdb)) then begin
res := empdb^;
writeln('By role : ', res.no, ' ', res.name, ' ', res.role);
end else begin
writeln('Key not found : role');
end;
close(empdb);
end.
identification division.
program-id.emp.
*
environment division.
input-output section.
file-control.
select empdb assign to "emp.isq"
organization is indexed
access mode is dynamic
record key is emp-no
alternate record key is emp-name with duplicates
alternate record key is emp-role with duplicates.
*
data division.
file section.
fd empdb.
01 employee.
03 emp-no pic x(4).
03 emp-name pic x(10).
03 emp-role pic x(10).
working-storage section.
*
procedure division.
main-paragraph.
display "Cobol"
open input empdb
move "0002" to emp-no
read empdb
invalid key display "Key not found : no"
not invalid key display "By no : " emp-no " " emp-name " " emp-role
end-read
move "Brian B " to emp-name
read empdb key is emp-name
invalid key display "Key not found : name"
not invalid key display "By name : " emp-no " " emp-name " " emp-role
end-read
move "Engineer " to emp-role
read empdb key is emp-role
invalid key display "Key not found : role"
not invalid key display "By role : " emp-no " " emp-name " " emp-role
end-read
close empdb
stop run.
program emp
option type = explicit
record employee
string no = 4
string empname = 10
string role = 10
end record
map (buf) employee res
print "Basic"
open "emp.isq" for input as file #1, indexed fixed, map buf, primary key res::no
handler nono_handler
print "Key not found : no"
end handler
when error use nono_handler
get #1, key #0 eq "0002"
print using "By no : 'E 'E 'E", res::no, res::empname, res::role
end when
handler noname_handler
print "Key not found : name"
end handler
when error use noname_handler
get #1, key #1 eq "Brian B "
print using "By name : 'E 'E 'E", res::no, res::empname, res::role
end when
handler norole_handler
print "Key not found : role"
end handler
when error use norole_handler
get #1, key #2 eq "Engineer "
print using "By role : 'E 'E 'E", res::no, res::empname, res::role
end when
close #1
end program
$ write sys$output "DCL"
$ open/read db emp.isq
$ dono:
$ read/index=0/key="0002"/err=nono db res
$ write sys$output f$fao("By no : !AS !AS !AS", f$extract(0, 4, res), f$extract(4, 10, res), f$extract(14, 10, res))
$ goto doname
$ nono:
$ write sys$output "Key not found : no"
$ doname:
$ read/index=1/key="Brian B "/err=noname db res
$ write sys$output f$fao("By name : !AS !AS !AS", f$extract(0, 4, res), f$extract(4, 10, res), f$extract(14, 10, res))
$ goto dorole
$ noname:
$ write sys$output "Key not found : name"
$ dorole:
$ read/index=2/key="Engineer "/err=norole db res
$ write sys$output f$fao("By rold : !AS !AS !AS", f$extract(0, 4, res), f$extract(4, 10, res), f$extract(14, 10, res))
$ goto finish
$ norole:
$ write sys$output "Key not found : role"
$ finish:
$ close db
$ exit
import dk.vajhoej.isam.KeyField;
import dk.vajhoej.record.FieldType;
import dk.vajhoej.record.Struct;
import dk.vajhoej.record.StructField;
@Struct
public class Employee {
@KeyField(n=0)
@StructField(n=0, type=FieldType.FIXSTR, length=4)
private String no;
@KeyField(n=1)
@StructField(n=1, type=FieldType.FIXSTR, length=10)
private String name;
@KeyField(n=2)
@StructField(n=2, type=FieldType.FIXSTR, length=10)
private String role;
public Employee() {
this(" ", " ", " ");
}
public Employee(String no, String name, String role) {
this.no = no;
this.name = name;
this.role = role;
}
public String getNo() {
return no;
}
public String getName() {
return name;
}
public String getRole() {
return role;
}
}
import dk.vajhoej.isam.IsamException;
import dk.vajhoej.isam.IsamResult;
import dk.vajhoej.isam.IsamSource;
import dk.vajhoej.isam.Key;
import dk.vajhoej.isam.Key0;
import dk.vajhoej.isam.local.LocalIsamSource;
import dk.vajhoej.record.RecordException;
public class Emp{
public static void main(String[] args) throws Exception {
System.out.println("Java");
IsamSource db = new LocalIsamSource("emp.isq", "dk.vajhoej.vms.rms.IndexSequential", true);
Employee res = db.read(Employee.class, new Key0<String>("0002"));
if(res != null) {
System.out.printf("By no : %s %s %s\n", res.getNo(), res.getName(), res.getRole());
} else {
System.out.println("Key not found : no");
}
res = db.read(Employee.class, new Key<String>(1, "Brian B "));
if(res != null) {
System.out.printf("By name : %s %s %s\n", res.getNo(), res.getName(), res.getRole());
} else {
System.out.println("Key not found : name");
}
res = db.read(Employee.class, new Key<String>(2, "Engineer "));
if(res != null) {
System.out.printf("By role : %s %s %s\n", res.getNo(), res.getName(), res.getRole());
} else {
System.out.println("Key not found : role");
}
db.close();
}
}
import dk.vajhoej.isam.KeyField;
import dk.vajhoej.record.FieldType;
import dk.vajhoej.record.Struct;
import dk.vajhoej.record.StructField;
@Struct
public class Employee {
@KeyField(n=0)
@StructField(n=0, type=FieldType.FIXSTR, length=4)
private String no;
@KeyField(n=1)
@StructField(n=1, type=FieldType.FIXSTR, length=10)
private String name;
@KeyField(n=2)
@StructField(n=2, type=FieldType.FIXSTR, length=10)
private String role;
public Employee() {
this(" ", " ", " ");
}
public Employee(String no, String name, String role) {
this.no = no;
this.name = name;
this.role = role;
}
public String getNo() {
return no;
}
public String getName() {
return name;
}
public String getRole() {
return role;
}
}
from dk.vajhoej.isam import Key
from dk.vajhoej.isam import Key0
from dk.vajhoej.isam import IsamException
from dk.vajhoej.isam.local import LocalIsamSource
import Employee
print('Jython')
db = LocalIsamSource('emp.isq', 'dk.vajhoej.vms.rms.IndexSequential', True)
res = db.read(Employee, Key0('0002'))
if res != None:
print('By no : %s %s %s' % (res.no, res.name, res.role))
else:
print('Key not found : no')
if res != None:
res = db.read(Employee, Key(1, 'Brian B '))
print('By name : %s %s %s' % (res.no, res.name, res.role))
else:
print('Key not found : name')
if res != None:
res = db.read(Employee, Key(2, 'Engineer '))
print('By role : %s %s %s' % (res.no, res.name, res.role))
else:
print('Key not found : role')
db.close()
from construct import *
from vms.rms.IndexedFile import IndexedFile
class Employee:
def __init__(self, no, name, role):
self.no = no
self.name = name
self.role = role
class DataFile(IndexedFile):
def __init__(self, fnm):
IndexedFile.__init__(self, fnm, Struct('employee', String('no', 4), String('name', 10), String('role', 10)))
def primary_keynum(self):
return 0
def pack_key(self, keynum, keyval):
return keyval
def keyval(self, rec, keynum):
if keynum == 0:
return rec.no
if keynum == 1:
return rec.name
if keynum == 2:
return rec.role
return None
print('Python')
db = DataFile('emp.isq')
rec = db.fetch(0, '0002')
if rec != None:
res = Employee(rec.no, rec.name, rec.role)
print('By no : %s %s %s' % (res.no, res.name, res.role))
else:
print('Key not found : no')
rec = db.fetch(1, 'Brian B ')
if rec != None:
res = Employee(rec.no, rec.name, rec.role)
print('By name : %s %s %s' % (res.no, res.name, res.role))
else:
print('Key not found : name')
rec = db.fetch(2, 'Engineer')
if rec != None:
res = Employee(rec.no, rec.name, rec.role)
print('By role : %s %s %s' % (res.no, res.name, res.role))
else:
print('Key not found : rold')
There are two different cases of changing file attributes:
This requires an actual file conversion.
It can be done by a custom conversion program or by DCL.
DCL has the CONVERT command for such task.
Example:
Convert any RFM to STMLF:
$ convert/fdl="record; format stream_lf" <input-file> <output-file>
or:
$ convert/fdl=<fdl-file> <input-file> <output-file>
where FDL file contains:
record
format stream_lf
Generally DCL is easier than a custom conversion program.
This can be done by a custom program using SYS$MODIFY or by DCL.
DCL has the SET FILE/ATTR command for such task.
Example:
Set file attributes to RFM STMLF:
$ set file/attr=rfm:stmlf <file>
Generally DCL is much easier than a custom program using SYS$MODIFY.
| Version | Date | Description |
|---|---|---|
| 1.0 | December 29th 2023 | Initial version |
| 1.1 | January 2nd 2024 | Add Groovy examples and seek examples, add section about max record size |
See list of all articles here
Please send comments to Arne Vajhøj