Memory mapped files may not be a feature that all developers know about.
This article try to give an introduction to memory mapped files.
Basically mapping a file to memory works like:
pointer_to_byte_array = map_file(filename) // access byte array by index unmap(pointer_to_byte_array)
When first seeing such usage, then many developers may think that it is pretty silly, because they expect an implementation like:
function map_file(filename) {
size = file_size(filename)
ptr = allocate(size)
read(filename, ptr, size)
return ptr
}
function unmap(ptr) {
if not readonly {
write(filename, ptr)
}
free(ptr)
}
and that would just be hopeless for big files.
A memory mapped file API could work that way, but on all common platforms it works completely differently in a way that makes much more sense.
Memory mapped files are tied closedly to the virtual memory systems that all main stream OS has today and the associated paging mechanism.
An OS *without* virtual memory may run an application conceptually like:
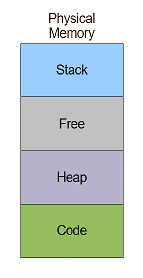
while an OS *with* virtual memory may run multiple applications conceptually like:
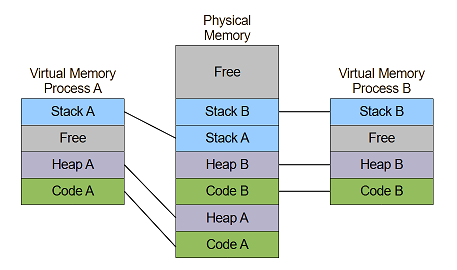
But what happens when there is not enough physical memory (RAM) for all programs?
Well in that case the OS use disk as backing storage. Heap data and stack data can be in pagefile instead of RAM. Code already exist on disk.
Conceptually that may look like:
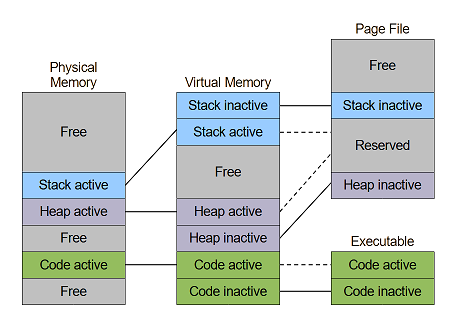
Today most computers has so much RAM that actual paging of data is rare. But the mechanism still exist in the OS.
And that mechanism can be used to map arbitrary data files into virtual memory.
Conceptually that may look like:
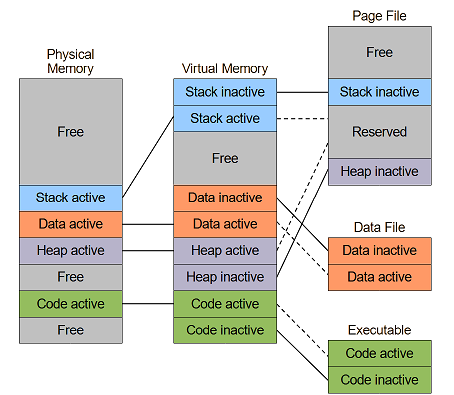
And that works great, because:
So with a memory mapped file then typical only the actual used parts of the file will be in memory. And that works well with big files.
Memory mapped files make most sense for big files, so we will demo with a 1 GB file.
The demo will test the time to count the number of lines. It is obviously not a realistic example, but it illustrates the technique.
The following 3 ways to read will be measured:
For memory mapped file the test code will read all bytes sequentially using a a random access API.
Java code:
package mapfile;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
public class Gen {
private static final int SIZE = 1000000000;
public static void main(String[] args) throws IOException {
System.out.printf("%s %s / %s %s\n", System.getProperty("java.vendor"), System.getProperty("java.version"), System.getProperty("os.name"), System.getProperty("os.version"));
long t1 = System.currentTimeMillis();
try(PrintWriter pw = new PrintWriter(new FileWriter(args[0]))) {
for(int i = 0; i < SIZE / 10; i++) {
for(int j = 0; j < 10 - System.getProperty("line.separator").length(); j++) {
pw.print(Integer.toString(i % 10));
}
pw.println();
}
}
long t2 = System.currentTimeMillis();
System.out.printf("Gen : %d ms\n", t2 - t1);
}
}
package mapfile;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Read1 {
private static void test(String fnm) throws IOException {
System.out.printf("%s %s / %s %s\n", System.getProperty("java.vendor"), System.getProperty("java.version"), System.getProperty("os.name"), System.getProperty("os.version"));
long t1 = System.currentTimeMillis();
List<String> lines = Files.readAllLines(Paths.get(fnm));
System.out.printf("%d lines\n", lines.size());
long t2 = System.currentTimeMillis();
System.out.printf("Read all lines : %d ms\n", t2 - t1);
}
public static void main(String[] args) throws IOException {
for(int i = 0; i < 3; i++) {
test(args[0]);
}
}
}
using System;
using System.IO;
namespace Read1
{
public class Program
{
private static void Test(string fnm)
{
Console.WriteLine("{0} / {1}", Environment.Version, Environment.OSVersion);
DateTime dt1 = DateTime.Now;
string[] lines = File.ReadAllLines(fnm);
Console.WriteLine("{0} lines", lines.Length);
DateTime dt2 = DateTime.Now;
Console.WriteLine("Read all lines : {0} ms", (dt2 - dt1).Ticks / TimeSpan.TicksPerMillisecond);
}
public static void Main(string[] args)
{
for(int i = 0; i < 3; i++)
{
Test(args[0]);
}
}
}
}
import mmap
import time
import sys
import platform
def test(fnm):
print('%s / %s' % (sys.version, platform.platform()))
with open(fnm, 'r') as f:
t1 = time.time()
lines = f.readlines()
print('%d lines' % (len(lines)))
t2 = time.time()
print('Read all lines : %d ms' % ((t2 - t1) * 1000.0))
for i in range(3):
test(sys.argv[1])
package mapfile;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class Read2 {
private static void test(String fnm) throws IOException {
System.out.printf("%s %s / %s %s\n", System.getProperty("java.vendor"), System.getProperty("java.version"), System.getProperty("os.name"), System.getProperty("os.version"));
long t1 = System.currentTimeMillis();
try(BufferedReader br = new BufferedReader(new FileReader(fnm))) {
int n = 0;
@SuppressWarnings("unused")
String line;
while((line = br.readLine()) != null) {
n++;
}
System.out.printf("%d lines\n", n);
}
long t2 = System.currentTimeMillis();
System.out.printf("Read one line at a time : %d ms\n", t2 - t1);
}
public static void main(String[] args) throws IOException {
for(int i = 0; i < 3; i++) {
test(args[0]);
}
}
}
#include <stdio.h>
#include "high_res_timer.h"
static void test(const char *fnm)
{
FILE *fp;
char line[1000];
TIMECOUNT_T t1, t2;
int n;
t1 = GET_TIMECOUNT;
fp = fopen(fnm, "r");
n = 0;
while(fgets(line, sizeof(line), fp))
{
n++;
}
printf("%d lines\n", n);
fclose(fp);
t2 = GET_TIMECOUNT;
printf("Read one line at a time : %d ms\n", (int)((t2 - t1) * 1000 / UNITS_PER_SECOND));
}
int main(int argc, char *argv[])
{
int i;
for(i = 0; i < 3; i++)
{
test(argv[1]);
}
return 0;
}
program Read2(input, output);
{$APPTYPE CONSOLE}
uses
SysUtils, Windows;
procedure test(fnm : string);
var
f : text;
line : string;
t1, t2 : Cardinal;
n : integer;
begin
t1 := GetTickCount;
assign(f, fnm);
reset(f);
n := 0;
while not eof(f) do begin
readln(f, line);
n := n + 1;
end;
writeln(n:1,' lines');
close(f);
t2 := GetTickCount;
writeln('Read one line at a time : ', (t2 - t1):1, ' ms');
end;
var
i : integer;
begin
for i := 1 to 3 do begin
test(paramStr(1));
end;
end.
[inherit('sys$library:pascal$lib_routines')]
program Read2(input, output);
type
string = varying[32767] of char;
procedure test(fnm : string);
var
f : text;
line : string;
t1, t2 : Cardinal;
n : integer;
begin
t1 := Clock;
open(f, fnm, old);
reset(f);
n := 0;
while not eof(f) do begin
readln(f, line);
n := n + 1;
end;
writeln(n:1,' lines');
close(f);
t2 := Clock;
writeln('Read one line at a time : ', (t2 - t1):1, ' ms');
end;
var
i : integer;
cmdlin : string;
begin
lib$get_foreign(resultant_string:=cmdlin.body,resultant_length:=cmdlin.length);
for i := 1 to 3 do begin
test(cmdlin);
end;
end.
using System;
using System.IO;
namespace Read2
{
public class Program
{
private static void Test(string fnm)
{
Console.WriteLine("{0} / {1}", Environment.Version, Environment.OSVersion);
DateTime dt1 = DateTime.Now;
using(StreamReader sr = new StreamReader(fnm))
{
int n = 0;
string line;
while((line = sr.ReadLine()) != null)
{
n++;
}
Console.WriteLine("{0} lines", n);
}
DateTime dt2 = DateTime.Now;
Console.WriteLine("Read one line at a time : {0} ms", (dt2 - dt1).Ticks / TimeSpan.TicksPerMillisecond);
}
public static void Main(string[] args)
{
for(int i = 0; i < 3; i++)
{
Test(args[0]);
}
}
}
}
import mmap
import time
import sys
import platform
def test(fnm):
print('%s / %s' % (sys.version, platform.platform()))
with open(fnm, 'r') as f:
t1 = time.time()
n = 0
for line in f:
n = n + 1
print('%d lines' % (n))
t2 = time.time()
print('Read one line at a time : %d ms' % ((t2 - t1) * 1000.0))
for i in range(3):
test(sys.argv[1])
Different languages/technologies have different API's available for memory mapped files.
Java comes with a builtin API since Java 1.4.
C use platform API's:
*) Note that today the *nix API is widely available. It can be used on Windows using Cygwin. It can be used on VMS as well.
Pascal also use platform API's. Delphi use the Win32 API. VMS Pascal us ethe VMS API.
.NET comes with a builtin API that are modelled closely to the Win32 API.
Python comes with a builtin API that are modelled after the *nix API.
package mapfile;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.channels.FileChannel.MapMode;
import java.nio.file.Paths;
public class Read3 {
private static final int OFFSET = 0;
private static final int SIZE = 1000000000;
private static void test(String fnm) throws IOException {
System.out.printf("%s %s / %s %s\n", System.getProperty("java.vendor"), System.getProperty("java.version"), System.getProperty("os.name"), System.getProperty("os.version"));
long t1 = System.currentTimeMillis();
try(FileChannel fc = FileChannel.open(Paths.get(fnm))) {
ByteBuffer bb = fc.map(MapMode.READ_ONLY, OFFSET, SIZE);
bb.rewind();
int n = 0;
for(int ix = 0; ix < SIZE; ix++) {
byte b = bb.get(ix);
if(b == '\n') {
n++;
}
}
System.out.printf("%d lines\n", n);
}
long t2 = System.currentTimeMillis();
System.out.printf("Map file to memory : %d ms\n", t2 - t1);
}
public static void main(String[] args) throws IOException {
for(int i = 0; i < 3; i++) {
test(args[0]);
}
}
}
#include <stdio.h>
#include <stdlib.h>
#include <windows.h>
#include "high_res_timer.h"
#define OFFSET 0
#define SIZE 1000000000
static void test(const char *fnm)
{
HANDLE f;
HANDLE mf;
char *b;
TIMECOUNT_T t1, t2;
int n, ix;
t1 = GET_TIMECOUNT;
f = CreateFile(fnm, GENERIC_READ, 0, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL);
if(f == INVALID_HANDLE_VALUE)
{
printf("Error opening file\n");
exit(1);
}
mf = CreateFileMapping(f, NULL, PAGE_READONLY, 0, SIZE, NULL);
if(mf == NULL)
{
printf("Error mapping file\n");
exit(1);
}
b = MapViewOfFile(mf, FILE_MAP_READ, 0, OFFSET, SIZE);
n = 0;
for(ix = 0; ix < SIZE; ix++)
{
if(b[ix] == '\n')
{
n++;
}
}
printf("%d lines\n", n);
CloseHandle(mf);
CloseHandle(f);
t2 = GET_TIMECOUNT;
printf("Map file to memory : %d ms\n", (int)((t2 - t1) * 1000 / UNITS_PER_SECOND));
}
int main(int argc, char *argv[])
{
int i;
for(i = 0; i < 3; i++)
{
test(argv[1]);
}
return 0;
}
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/mman.h>
#include "high_res_timer.h"
#define OFFSET 0
#define SIZE 1000000000
static void test(const char *fnm)
{
int fd;
char *b;
TIMECOUNT_T t1, t2;
int n, ix;
t1 = GET_TIMECOUNT;
fd = open(fnm, O_RDONLY);
if(fd == -1)
{
printf("Error opening file\n");
exit(1);
}
b = mmap(NULL, SIZE, PROT_READ, MAP_PRIVATE, fd, OFFSET);
if(b == MAP_FAILED)
{
printf("Error mapping file\n");
exit(1);
}
n = 0;
for(ix = 0; ix < SIZE; ix++)
{
if(b[ix] == '\n')
{
n++;
}
}
printf("%d lines\n", n);
munmap(b, SIZE);
close(fd);
t2 = GET_TIMECOUNT;
printf("Map file to memory : %d ms\n", (int)((t2 - t1) * 1000 / UNITS_PER_SECOND));
}
int main(int argc, char *argv[])
{
int i;
for(i = 0; i < 3; i++)
{
test(argv[1]);
}
return 0;
}
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <fabdef.h>
#include <secdef.h>
#include <starlet.h>
#define PAGE_SIZE 8192
#define PAGELET_SIZE 512
#define DISKBLOCK_SIZE 512
#define BY2U(n, unit_size) (n - 1) / unit_size + 1
#include "high_res_timer.h"
#define OFFSET 0
#define SIZE 1000000000
static void test(char *fnm)
{
struct FAB myfab;
void *range[2];
unsigned short chan;
long int stat;
char *b;
TIMECOUNT_T t1, t2;
int n, ix;
t1 = GET_TIMECOUNT;
myfab = cc$rms_fab;
myfab.fab$l_fna = fnm;
myfab.fab$b_fns = strlen(fnm);
myfab.fab$l_fop = FAB$M_UFO;
myfab.fab$b_fac = FAB$M_GET;
stat = sys$open(&myfab, 0, 0);
if((stat & 1) == 0)
{
printf("Error opening file\n");
exit(1);
}
range[0] = 0;
range[1] = 0;
chan = myfab.fab$l_stv;
stat = sys$crmpsc(range, range, 0, SEC$M_EXPREG, 0, 0, 0, chan, BY2U(SIZE, PAGELET_SIZE), BY2U(OFFSET, DISKBLOCK_SIZE), 0, 0);
if((stat & 1) == 0)
{
printf("Error mapping file\n");
exit(1);
}
b = range[0];
n = 0;
for(ix = 0; ix < SIZE; ix++)
{
if(b[ix] == '\n')
{
n++;
}
}
printf("%d lines\n", n);
sys$deltva(range, 0, 0);
sys$close(&myfab, 0, 0);
t2 = GET_TIMECOUNT;
printf("Map file to memory : %d ms\n", (int)((t2 - t1) * 1000 / UNITS_PER_SECOND));
}
int main(int argc, char *argv[])
{
int i;
for(i = 0; i < 3; i++)
{
test(argv[1]);
}
return 0;
}
program Read3;
{$APPTYPE CONSOLE}
uses
SysUtils, Windows;
procedure test(fnm : string);
const
OFFSET = 0;
SIZE = 1000000000;
type
data = packed array [1..SIZE] of char;
var
f : THandle;
mf : THandle;
b : ^data;
t1, t2 : Cardinal;
n, ix : integer;
begin
t1 := GetTickCount;
f := CreateFile(PChar(fnm), GENERIC_READ, 0, nil, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, 0);
if f = INVALID_HANDLE_VALUE then begin
writeln('Error opening file');
halt;
end;
mf := CreateFileMapping (f, nil, Page_ReadOnly, 0, SIZE, nil);
if mf = 0 then begin
writeln('Error mapping file');
halt;
end;
b := MapViewOfFile(mf, FILE_MAP_READ, 0, OFFSET, SIZE);
n := 0;
for ix := 1 to SIZE do begin
if b^[ix] = chr(10) then begin
n := n + 1;
end;
end;
writeln(n:1,' lines');
CloseHandle(mf);
CloseHandle(f);
t2 := GetTickCount;
writeln('Read one line at a time : ', (t2 - t1):1, ' ms');
end;
var
i : integer;
begin
for i := 1 to 3 do begin
test(paramStr(1));
end;
end.
[inherit('sys$library:pascal$lib_routines', 'sys$library:starlet')]
program Read3(input, output);
type
string = varying[32767] of char;
word = [word] 0..65535;
procedure test(fnm : string);
const
PAGE_SIZE = 8192;
PAGELET_SIZE = 512;
DISKBLOCK_SIZE = 512;
OFFSET = 0;
SIZE = 1000000000;
function BY2U(n : integer; unit_size : integer) : integer;
begin
BY2U := (n - 1) div unit_size + 1;
end;
type
data = packed array [1..SIZE] of char;
var
myfab : fab$type;
range : array [1..2] of pointer;
chan : word;
stat : integer;
b : ^data;
t1, t2 : Cardinal;
n, ix : integer;
begin
t1 := Clock;
myfab.fab$b_bid := FAB$C_BID;
myfab.fab$b_bln := FAB$C_BLN;
myfab.fab$l_fna := iaddress(fnm.body);
myfab.fab$b_fns := fnm.length;
myfab.fab$l_fop := FAB$M_UFO;
myfab.fab$b_fac := FAB$M_GET;
myfab.fab$w_ifi := 0;
myfab.fab$b_shr := 0;
myfab.fab$l_nam := 0;
stat := $open(fab := myfab);
if not odd(stat) then begin
writeln('Error opening file');
halt;
end;
range[1] := nil;
range[2] := nil;
chan := myfab.fab$l_stv;
stat := $crmpsc(inadr := range, retadr := range, flags := SEC$M_EXPREG, chan := chan, pagcnt := BY2U(SIZE, PAGELET_SIZE), vbn := BY2U(OFFSET, DISKBLOCK_SIZE));
if not odd(stat) then begin
writeln('Error mapping file');
halt;
end;
b := range[1];
n := 0;
for ix := 1 to SIZE do begin
if b^[ix] = chr(10) then begin
n := n + 1;
end;
end;
writeln(n:1,' lines');
$deltva(inadr := range);
$close(fab := myfab);
t2 := Clock;
writeln('Read one line at a time : ', (t2 - t1):1, ' ms');
end;
var
i : integer;
cmdlin : string;
begin
lib$get_foreign(resultant_string:=cmdlin.body,resultant_length:=cmdlin.length);
for i := 1 to 3 do begin
test(cmdlin);
end;
end.
using System;
using System.IO;
using System.IO.MemoryMappedFiles;
namespace Read3
{
public class Program
{
private const int OFFSET = 0;
private const int SIZE = 1000000000;
private static void Test(string fnm)
{
Console.WriteLine("{0} / {1}", Environment.Version, Environment.OSVersion);
DateTime dt1 = DateTime.Now;
using (MemoryMappedFile mmf = MemoryMappedFile.CreateFromFile(fnm, FileMode.Open))
{
using(MemoryMappedViewAccessor mmva = mmf.CreateViewAccessor(OFFSET, SIZE, MemoryMappedFileAccess.Read))
{
int n = 0;
for(int ix = 0; ix < SIZE; ix++)
{
byte b = mmva.ReadByte(ix);
if(b == '\n')
{
n++;
}
}
Console.WriteLine("{0} lines", n);
}
}
DateTime dt2 = DateTime.Now;
Console.WriteLine("Map file to memory : {0} ms", (dt2 - dt1).Ticks / TimeSpan.TicksPerMillisecond);
}
public static void Main(string[] args)
{
for(int i = 0; i < 3; i++)
{
Test(args[0]);
}
}
}
}
import mmap
import time
import sys
import platform
SIZE = 1000000000
def test(fnm):
print('%s / %s' % (sys.version, platform.platform()))
with open(fnm, 'r+b') as f:
t1 = time.time()
mm = mmap.mmap(f.fileno(), SIZE, access=mmap.ACCESS_READ)
n = 0
for ix in range(SIZE):
mm.seek(ix)
b = mm.read_byte()
if b == ord('\n') or b == '\n': # little trick - the first works with Python 3.x - the second works with Python 2.x
n = n + 1
print('%d lines' % (n))
t2 = time.time()
print('Map file to memory : %d ms' % ((t2 - t1) * 1000.0))
for i in range(3):
test(sys.argv[1])
Here are some results for various configurations:
| Language | OS | Disk type | Read all lines | Read one line at a time | Map file to memory |
|---|---|---|---|---|---|
| Java 17 | Windows 10 | SSD | 5868 | 3507 | 636 |
| Java 17 | Windows 10 | HDD | 6475 | 3447 | 653 |
| MSVC++ 19 - Win32 API | Windows 10 | SSD | N/A | 6243 | 743 |
| MSVC++ 19 - Win32 API | Windows 10 | HDD | N/A | 6433 | 761 |
| GCC 11 - *nix API | Windows 10 + Cygwin | SSD | N/A | 7739 | 610 |
| GCC 11 - *nix API | Windows 10 + Cygwin | HDD | N/A | 8009 | 582 |
| FPC 3 - Win32 API | Windows 10 | SSD | N/A | 32672 | 1125 |
| FPC 3 - Win32 API | Windows 10 | HDD | N/A | 31484 | 1172 |
| .NET 4 | Windows 10 | SSD | OutOfMemoryException | 3750 | 69019 |
| .NET 4 | Windows 10 | HDD | OutOfMemoryException | 3633 | 69706 |
| .NET 7 | Windows 10 | SSD | 14111 | 3329 | 17510 |
| .NET 7 | Windows 10 | HDD | 13304 | 3017 | 16845 |
| CPython 3.11 | Windows 10 | SSD | 10559 | 12275 | 152126 |
| CPython 3.11 | Windows 10 | HDD | 10621 | 11486 | 149158 |
| CPython 2.7 | Windows 10 | SSD | 7371 | 6157 | 233756 |
| CPython 2.7 | Windows 10 | HDD | 7485 | 5996 | 234865 |
| PyPy 3.10 | Windows 10 | SSD | 40431 | 8442 | 2573 |
| PyPy 3.10 | Windows 10 | HDD | 35070 | 8206 | 2710 |
| PyPy 2.7 | Windows 10 | SSD | 21898 | 118418 | 4710 |
| PyPy 2.7 | Windows 10 | HDD | 23175 | 117784 | 4973 |
| Java 17 | Ubuntu / Linux kernel 5 | SSD | OutOfMemoryError | 3282 | 401 |
| GCC 11 *nix API | Ubuntu / Linux kernel 5 | SSD | N/A | 2407 | 188 |
| .NET 7 | Ubuntu / Linux kernel 5 | SSD | 15550 | 2917 | 17315 |
| CPython 3.10 | Ubuntu / Linux kernel 5 | SSD | 8882 | 6484 | 160869 |
| CPython 2.7 | Ubuntu / Linux kernel 5 | SSD | 4332 | 3878 | Killed |
| GraalPython 3.10 / Java 17 | Ubuntu / Linux kernel 5 | SSD | Killed | 8756 | 55210 |
| Java 8 | VMS 8.4 Itanium (*) | HDD | Manually aborted after 8 minutes | 1514 | 559 |
| C - VMS API | VMS 8.4 Itanium (*) | HDD | N/A | 2927 | 358 |
| C - *nix API | VMS 8.4 Itanium (*) | HDD | N/A | 2927 | 454 |
| VMS Pascal - VMS API | VMS 8.4 Itanium (*) | HDD | N/A | 31040 | 510 |
| Python 3.10 | VMS 8.4 Itanium (*) | HDD | 8319 | 17141 | 345261 |
*) On VMS Itanium the file is only 100 MB not 1 GB to compensate for old HW, old SW and traditional slow IO on VMS. The VMS file is in Stream LF record format - not Variable record format.
We see that the benefits of memory mapped files vary a lot by language.
| Language | Memory Mapped Files |
|---|---|
| C other native languages (Pascal etc.) Java |
Good |
| newer .NET PyPy |
OK |
| older .NET Python except PyPy |
Bad |
We see that the benfits of memory mapped files does not vary much for the OS tested (but it may for other OS!).
We see that the benfits of memory mapped files does not vary much for disk type (SSD vs HDD). This is somewhat unexpected, but could be due to the fact that even though the file is big (1 GB) then it can still be cached in memory.
If one need to process big files and performance is important then memory mapped files are woth considering.
But decision will depend on language and platform. Doing some research is a must before going with memory mapped files.
Also note that even though memory mapped files may be an efficient technique, then it is also a very low level technique exposing the physical file format to the application. Example: for a text file it will be visible to the application code whether the platform use CRLF like Windows, LF like *nix or a more complex format. That should also be considered before going with memory mapped files.
The demo above was accessing the file in readonly mode. That may be the most common use case, but it is also possible to access the file as readwrite.
When having a readwrite memory mapped file, then it can be used as a no effort database. All changes to memory data structures get persisted to the file by the OS without any update/save code in the application.
Let us see an example.
The example will be using C, because more high level languages typical already have features to make very easy persistence (ORM, NoSQL databases exposing a collection API etc.).
The example will be using the *nix API as it is more portable than any other C API.
(tested on Windows with Cygwin and GCC)
We start with some non-persisting in-memory-only code.
data.h:
#ifndef DATA_H
#define DATA_H
#define MAX_NAME_LEN 50
#define MAX_NO_ITEMS 100
struct data_header
{
int no_items;
};
struct data_item
{
int id;
char name[MAX_NAME_LEN + 1];
int val;
};
struct data_footer
{
int sum_val;
};
struct data
{
struct data_header header;
struct data_item items[MAX_NO_ITEMS];
struct data_footer footer;
};
void data_add_item(struct data *data_ptr, int id, const char *name, int val);
void data_dump(struct data *data_ptr, FILE *dumpfp);
#endif
data.c:
#include <stdio.h>
#include <string.h>
#include "data.h"
void data_add_item(struct data *data_ptr, int id, const char *name, int val)
{
/* update item in memory */
data_ptr->items[data_ptr->header.no_items].id = id;
strcpy(data_ptr->items[data_ptr->header.no_items].name, name);
data_ptr->items[data_ptr->header.no_items].val = val;
/* update header in memory */
data_ptr->header.no_items++;
/* update footer in memory */
data_ptr->footer.sum_val += val;
}
void data_dump(struct data *data_ptr, FILE *dumpfp)
{
int i;
fprintf(dumpfp, "header: no_items = %d\n", data_ptr->header.no_items);
for(i = 0; i < data_ptr->header.no_items; i++)
{
fprintf(dumpfp, "item: (%d,%s,%d)\n", data_ptr->items[i].id, data_ptr->items[i].name, data_ptr->items[i].val);
}
fprintf(dumpfp, "footer: sum_val = %d\n", data_ptr->footer.sum_val);
}
test.c:
#include <stdio.h>
#include <stdlib.h>
#include "data.h"
int main()
{
struct data *data_ptr;
/* setup memory */
data_ptr = malloc(sizeof(struct data));
data_ptr->header.no_items = 0;
data_ptr->footer.sum_val = 0;
/* work */
data_add_item(data_ptr, 1, "A A", 123);
data_add_item(data_ptr, 2, "B B", 456);
data_add_item(data_ptr, 3, "C C", 789);
data_dump(data_ptr, stdout);
/* teatdown memory */
free(data_ptr);
/* */
return 0;
}
Rather trivial code.
Obviously data_add_item should check for overflow, but that is besides what we are trying to show.
Now comes a new requirement: persist the data so they are kept between runs. And without writing the entire file every time (not a problem for this example as data is only 6 KB, but if data was 6 TB, then it would be a problem).
The traditional approach would be to update on disk after each update.
datax.h:
#ifndef DATAX_H
#define DATAX_H
#define MAX_NAME_LEN 50
#define MAX_NO_ITEMS 100
struct data_header
{
int no_items;
};
struct data_item
{
int id;
char name[MAX_NAME_LEN + 1];
int val;
};
struct data_footer
{
int sum_val;
};
struct data
{
struct data_header header;
struct data_item items[MAX_NO_ITEMS];
struct data_footer footer;
};
void datax_add_item(struct data *data_ptr, int id, const char *name, int val, FILE *dbfp);
void datax_dump(struct data *data_ptr, FILE *dumpfp);
#endif
datax.c:
#include <stdio.h>
#include <string.h>
#include "datax.h"
void datax_add_item(struct data *data_ptr, int id, const char *name, int val, FILE *dbfp)
{
/* update item in memory */
data_ptr->items[data_ptr->header.no_items].id = id;
strcpy(data_ptr->items[data_ptr->header.no_items].name, name);
data_ptr->items[data_ptr->header.no_items].val = val;
/* update item on disk */
fseek(dbfp, sizeof(struct data_header) + data_ptr->header.no_items * sizeof(struct data_item), SEEK_SET);
fwrite(&data_ptr->items[data_ptr->header.no_items], sizeof(struct data_item), 1, dbfp);
/* update header in memory */
data_ptr->header.no_items++;
/* update header on disk */
fseek(dbfp, 0, SEEK_SET);
fwrite(&data_ptr->header, sizeof(struct data_header), 1, dbfp);
/* update footer in memory */
data_ptr->footer.sum_val += val;
/* update footer on disk */
fseek(dbfp, sizeof(struct data_header) + MAX_NO_ITEMS * sizeof(struct data_item), SEEK_SET);
fwrite(&data_ptr->footer, sizeof(struct data_footer), 1, dbfp);
}
void datax_dump(struct data *data_ptr, FILE *dumpfp)
{
int i;
fprintf(dumpfp, "header: no_items = %d\n", data_ptr->header.no_items);
for(i = 0; i < data_ptr->header.no_items; i++)
{
fprintf(dumpfp, "item: (%d,%s,%d)\n", data_ptr->items[i].id, data_ptr->items[i].name, data_ptr->items[i].val);
}
fprintf(dumpfp, "footer: sum_val = %d\n", data_ptr->footer.sum_val);
}
testx.c:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "datax.h"
#define DBFNM "data.dat"
int main()
{
FILE *dbfp;
struct data *data_ptr;
/* setup memory and file */
data_ptr = malloc(sizeof(struct data));
dbfp = fopen(DBFNM, "r+b");
if(dbfp == NULL)
{
dbfp = fopen(DBFNM, "wb");
memset(data_ptr, 0, sizeof(struct data));
fwrite(data_ptr, sizeof(struct data), 1, dbfp);
fclose(dbfp);
dbfp = fopen(DBFNM, "r+b");
}
fread(data_ptr, sizeof(struct data), 1, dbfp);
/* work */
datax_add_item(data_ptr, 1, "A A", 123, dbfp);
datax_add_item(data_ptr, 2, "B B", 456, dbfp);
datax_add_item(data_ptr, 3, "C C", 789, dbfp);
datax_dump(data_ptr, stdout);
/* teardown memory and file */
fclose(dbfp);
free(data_ptr);
return 0;
}
It works fine, but it is a very intrusive change as persisting code has to be inserted everywhere in data updating code.
But there is an alternative approach using memory mapped file.
testm.c:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <errno.h>
#include "data.h"
#define DBFNM "data.dat"
int main()
{
int dbfd;
struct data *data_ptr;
/* setup memory and file */
dbfd = open(DBFNM, O_RDWR);
if(dbfd == -1)
{
dbfd = open(DBFNM, O_WRONLY | O_CREAT, S_IRUSR | S_IWUSR);
data_ptr = malloc(sizeof(struct data));
memset(data_ptr, 0, sizeof(struct data));
write(dbfd, data_ptr, sizeof(struct data));
free(data_ptr);
close(dbfd);
dbfd = open(DBFNM, O_RDWR);
}
data_ptr = mmap(NULL, sizeof(struct data), PROT_READ | PROT_WRITE, MAP_SHARED, dbfd, 0);
/* work */
data_add_item(data_ptr, 1, "A A", 123);
data_add_item(data_ptr, 2, "B B", 456);
data_add_item(data_ptr, 3, "C C", 789);
data_dump(data_ptr, stdout);
/* ensure data are persisted */
msync(data_ptr, sizeof(struct data), MS_SYNC);
/* teardown memory and file */
munmap(data_ptr, sizeof(struct data));
close(dbfd);
/* */
return 0;
}
No changes at all to the data updating code at all. The above uses the same functions as the in-memory-only example. The code just update memory and the OS do the persisting transparently.
If a readwrite memory mapped file is accessed in shared mode, then it can be used for communication between processes. And due to persistence then the processes is not required to be running at the same time.
For an example see VMS code here.
Note that this may require some external synchronization to work reliable in many cases.
| Version | Date | Description |
|---|---|---|
| 1.0 | July 30th 2023 | Initial version |
See list of all articles here
Please send comments to Arne Vajhøj